
系统设计具体流程
估算qps第1步 :了解问题并确定设计范围
需要开发什么功能
多少个人使用
技术栈是什么
最重要的功能是什么,是按照什么顺序排列的
流量多大,可以包含什么格式
第2步:提出高层次的设计方案并获得认同service,具体的服务
第三步就是选择数据库storage
总结
第1步 理解问题并确定设计范围:3-10分钟
第2步 提出高层次的设计并获得认同:10-15分钟
第3步 深入设计:10-25分钟
第4步 总结:3-5分钟
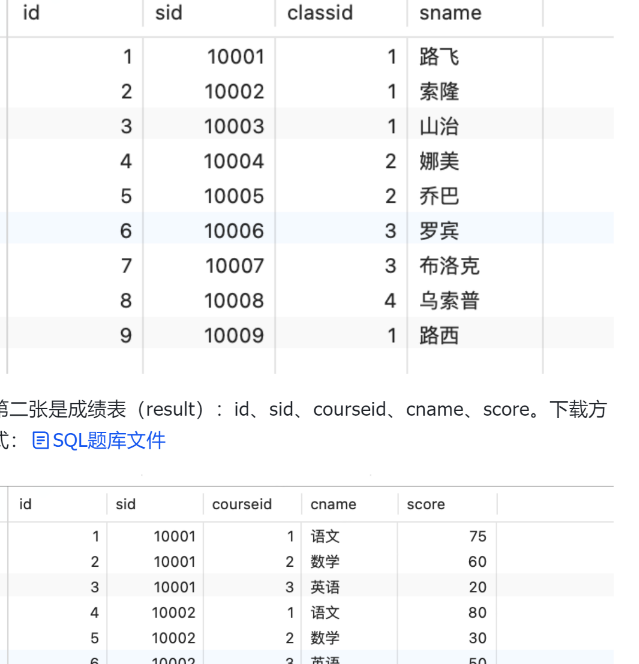
数据库题解
索隆各科成绩123select b.sname, c.sid , c.cname,c.score FROM result AS c , student AS bwhere c.sid = b.sid and b.sname="索隆"
打印出路飞的数学成绩(百度)12345select b.sname, c.sid , c.cname,c.score FROM result AS c , student AS bwhere c.sid = b.sid and b.sname="路飞"AND c.cname="数学"
打印出1班数学前2名的学生信息(百度)123456select b.sname, c.sid , c.cname,c.score FROM result AS c , student AS bwhere c.sid = b.sid and b.classid=1AND c.cname="数学"ORDER BY c.score descLIMIT 2
求各个科目前3名的学生(腾讯)12 ...

经典算法题目
239
491
450(把right挂到左子树的最右边就行,然后返回左边的值
669
42
84
376
518
377
209
115
1262
44
442
572 双重dfs
31
378
215
678
lcr120
287链表赵环
1044
912堆排序,只需要一直往下swqp,然后进行交换头节点
295对顶堆
394,两个st,然后对s遍历,【的时候进行清0,】的时候进行放入数据res
155 双栈,直接保存结果
400
lcr158 abc表示下一个位置,抽数
主要是使用数学题目
多线程代码交替答应1001234567891011121314151617181920212223242526272829303132333435363738394041424344454647package com.weijia.test.multiProcess;public class lab1 { // 使用sync,wait与notify来进行 private int cnt = 1; p ...
常用的api
char字符串进行加减法
1234567891011使用ord(c)来获得unicode代码,之后chr来进行编码回去s = list(s)for i,c in enumerate(s): dis = min(ord(c)-ord('a'), ord('z')-ord(c)+1) if dis <= k: s[i] = 'a' k -= dis else: s[i]=chr(ord(c)-k) break return ''.join(s)
字典1rec.get(num,0) #不存在默认返回,与java类似,存在直接使用rec[num]
优先队列直接使用get还有put来操作
需要借助list,存放数据
heapq是操作方法函数,然后使用push
1heapq.heappush(heap,(value,key))
移除
也是借助heap来进行heappop,heap[0][0]已经是最小的
默认是最小堆
1 ...
k8s wsl部署问题汇总
wsl部署k8s,直接安装docker windows进行打开k8s就行,
不需要自己遭罪的使用什么脚本来安装
deployment部署内容,使用的spec作为container来实现容器部署,container里面进行定义image镜像,副本数量,镜像端口,这个镜像是docker对dockerfile打包生成的image,可以使用makefile来进行简化流程。
makefile 定义打包流程,dockerfile设置基础镜像,然后把使用交叉编译得到的产物复制到镜像空间里面,之后运行产物。
123456789FROM ubuntu:20.04#复制产物到imageCOPY webook /app/webookWORKDIR /app#执行ENTRYPOINT ["/app/webook"]
12345678.PHONY:dockerdocker: @rm webook || true @GOOS=linux GOARCH=amd64 go build -o webook . @docker rmi -f flycash/webook:v0.0.1 @doc ...
场景面试相关问题
主要包括智力题还有海量数据题目和系统设计的场景题目。

java基础问题
重写的范围综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变。
方法的重写要遵循两同两小一大”(以下内容摘录自《疯狂]va讲义》):
·“两同”即方法名相同、形参列表相同;
·“两小”指的是子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等:
相当于就是返回子类是可以的,继承返回孩子类型
·“一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等。
可变参数这个和go里面差不多也是使用string…. args
string 问题stringbuffer和string都是线程安全的,因为有锁
builder知识构造者,不是线程安全的
string是private final数组,不可以变,无人更改,没法继承,jdk9是byte,为了支持拉丁文
string的+=重载符号是调用stringbuilder的append来进行构建的,这样会创建多个builder导致出现缓冲问题
intern:是为了将string放入常量池
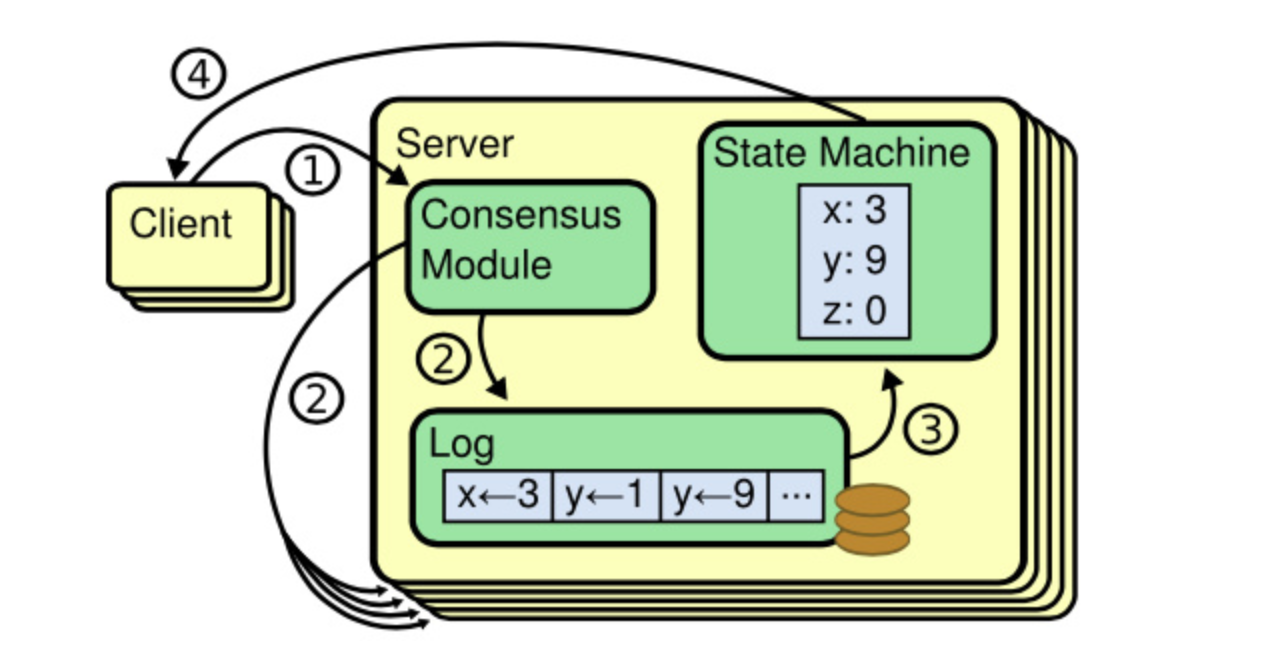
raft实现
raft论文介绍主要流程图
图 1 :复制状态机的结构。一致性算法管理着来自客户端指令的复制日志。状态机从日志中处理相同顺序的相同指令,所以产生的结果也是相同的。
:::info通过一致性传送log,发送指令,最终达到状态机一致
:::
关键词
follower
candidate
leader
只有candidate才可以变成leader,follower发送心跳,找不到leader,自己尝试开始变成candidate,然后发起新的一轮选举,选举得票数超过一半,才可以变成leader。(注意判断如何得到票数,是根据term任期的大小来决定的,如果对方的term大于当前自我的term,我就有candidate变成follower
:::info这就有三个函数,becomeleader,becomecandidate,becomefollo
:::
raft解决思路
领导选举
日志复制
一致性安全
状态:所有服务器上的持久性状态 (在响应 RPC 请求之前,已经更新到了稳定的存储设备)
参数
解释
currentTerm
服务器已知最新的任期(在服务器首次启动 ...
nlp任务
情感类别分类整体的思路就是,进行数据清洗,然后设置编码的时候,把fp函数首先经过tokenlization,之后设置label是数据集上的label,然后进行返回。使用分类模型。之后的评估函数是f1还有acc,然后设置trainer
读取ds
分割ds
对数据集使用map进行fp变换
设置model
之后设置评估acc
然后设置trainer
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArgumentsfrom datasets import load_datasetdataset = load_dataset("csv", data_files=&q ...
es
问题引入
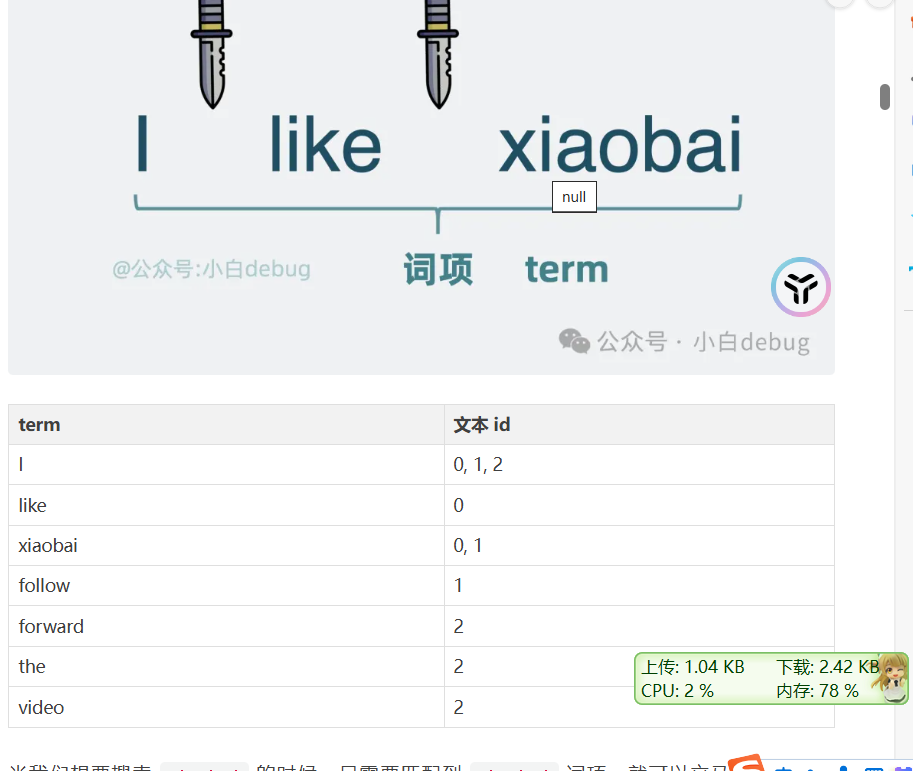
倒排序,就是通过搜索引擎输入关键词,插入出文章,改怎么处理
使用倒排索引,就是进行切词,然后根据词语,设置哪些文章出现了这个词语
但是这样查询就是ON的复杂度,一个个查询单词,因此可以使用字典树
单词+出现的列表就构成了倒排索引
因为数据太大,只能放入到disk里面
term index数据压缩,有共同的前缀,不需要一个个单词出现
stored fields之前查询的是文档id,需要id查到内容,存放完整的内容就是stored
doc value是将文档id映射到对应的字段,例如文档是一个手机的介绍,他就映射到时间是什么时候产的,价格是多少
segment就是上面的合并
lucene并发读取segment,小的segment定期进行合并
高性能也是按照之前kafka的思路优化,切分为不同的topic,这里的就是index name1
之后再次按照kafka更新的思路,切换为不同分区,这里是叫做shard
高扩展性照样参考kafka,这个是broker编程node
高可用性参考kafka的leader
node角色化这个是参考gfs,分为master,数据 ...

