
场景题目
两种思路,一个是4个d
- 询问场景,询问qps,主要业务,业务流程
- 询问服务,主要是暴露什么接口
- 接下来就是storage,使用什么数据库还有schma,为什么不用其他
- 接下来就是看还有没有优化的,进行防止盗刷,限流什么的
还有caps
- 沟通c,进行交流,业务逻辑,qps,精准度要求(能不能多卖,还是少买),难点分析
- a架构,服务,存储,流程
- p观点展开,难点1,难点2
- s总结,开场出结论,然后索引要点
秒杀专题
c对话
主要询问qps,业务流程,难点
主要的业务流程:首先是查询时间是否到了秒杀时间,之后开始秒杀,是否还有名额,然后进行购买,秒杀库存,之后生辰订单,付款
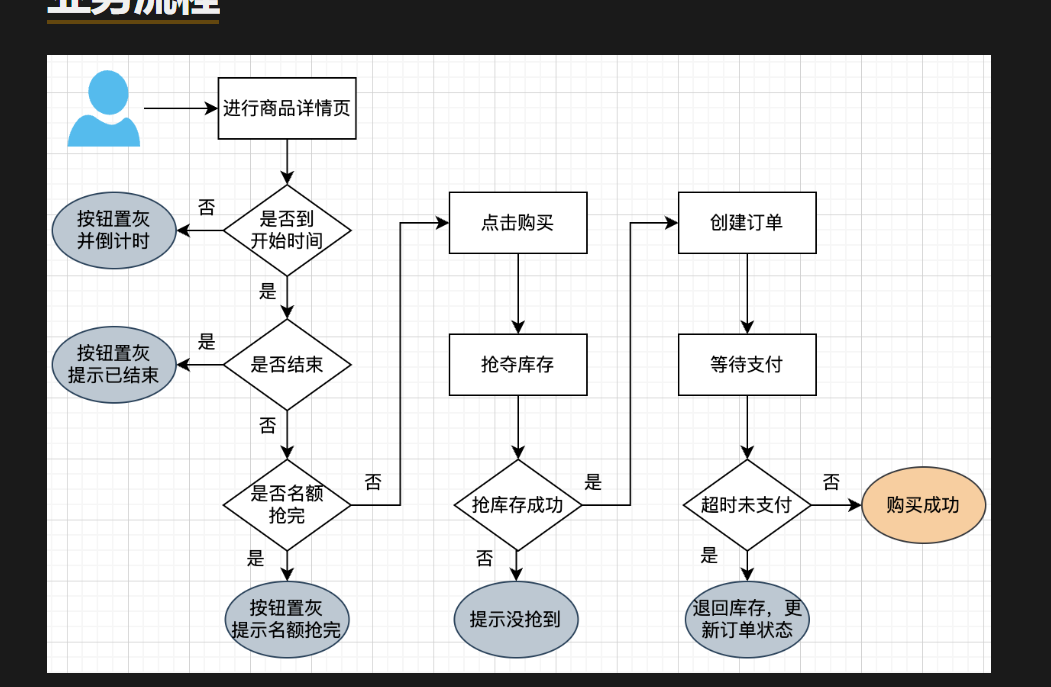
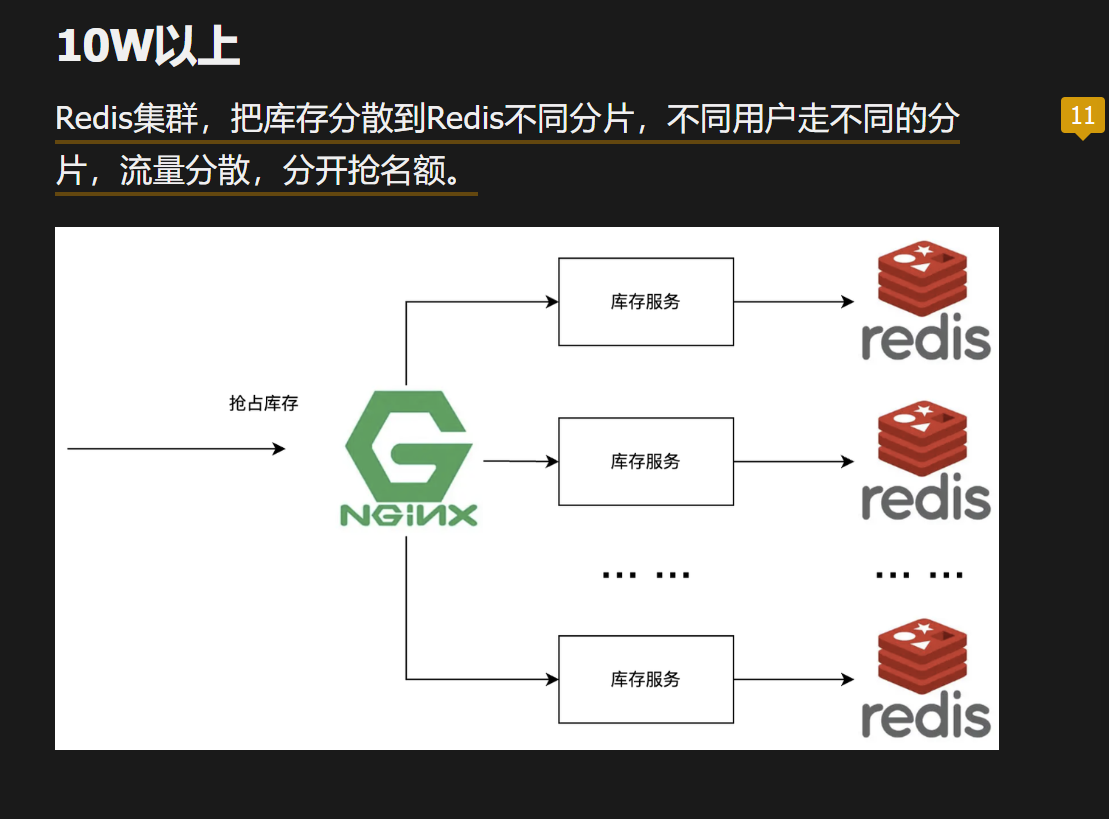
请求量估计,如果是一般的5k,单个mysql就行,1w两个mysql,超过直接上redis,10w之后就是集群,每一个redis配置下平均的秒杀数量
超卖与少买的问题,使用redis、
- redis寄了,丢掉命令
- 主从切换,丢了
- 查询不是原子的
少买
- 库存减少,但是订单失败
- 用户不付款,回滚失败
难点分析
- 高并发,人流量大-风控,限流,验证码,薛峰
- 高精准
- 大吉黄牛,进行限额
架构设计
主要是进行服务,存储来设计
服务方面
- 商品信息
- 秒杀信息
- 与扣减库存
- 库存数量
- 订单服务
数据库方面
设计表,信息表,mysql秒杀记录表(订单编号,秒杀编号,用户id,抢购数量,状态
整体服务流程
- 拉取信息秒杀
- 开始抢购,使用redis来获取,丢进kafka来进行生成订单
- 消耗库存,写入到订单里面,更新redis学习
要点分析
具体的难点分析,主要是scale
是否超过限额
前端得到秒杀状态,通过轮训redis信息
lua脚本进行与扣减,不会超卖的原因是乐观锁,stock》=1
退回逻辑:直接轮训mysql的值
黄牛:进行限流
总结
不同量级的秒杀是不一样 的,常见的几十万qps,高并发使用消息队列和redis,精准通过mysql来避免
扫码登录实现
c沟通
主要了解业务流程,还有qps和难点,就是了解场景
具体流程
- 展示二维码
- 手机扫码出现头像信息
- 然后就是手机确认
- 之后登录
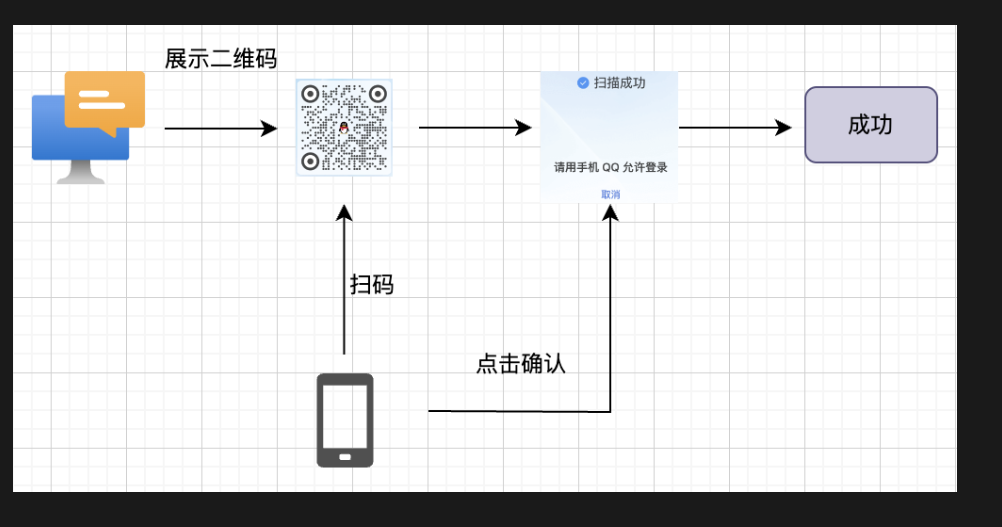
因此需要二维码服务器,
难点,是唯一一个电脑在线
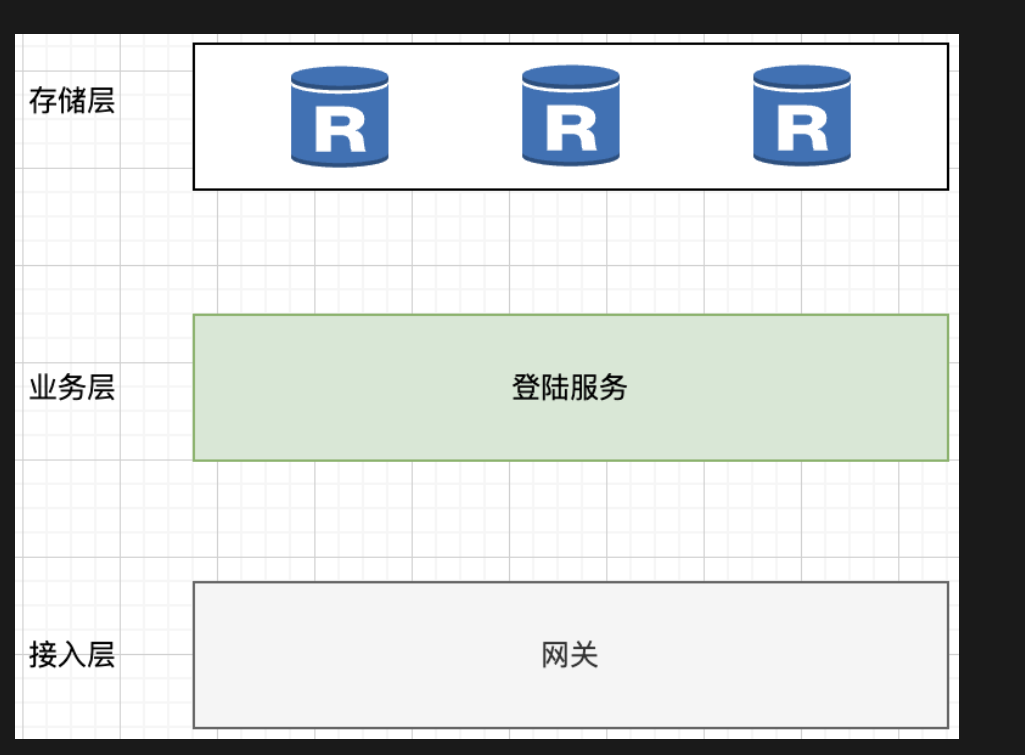
服务设计
考虑服务还有存储
服务
- 登录服务
数据库
- 一个设备对应一个token,使用token鉴权
- redis进行存放
具体流程
- pc产生二维码id,并且把二维码id与这个电脑放到redis
- 电脑轮训得到展示
- 扫码,请求发送服务端,关联uid与二维码id,更新二维码状态
- 使用临时token登录,然后生成新的pctoken与电脑
要点总结
主要三个流程,第一个就是首先生成token的时候,之后就是扫码时候,最后就是确认之后
schema编排
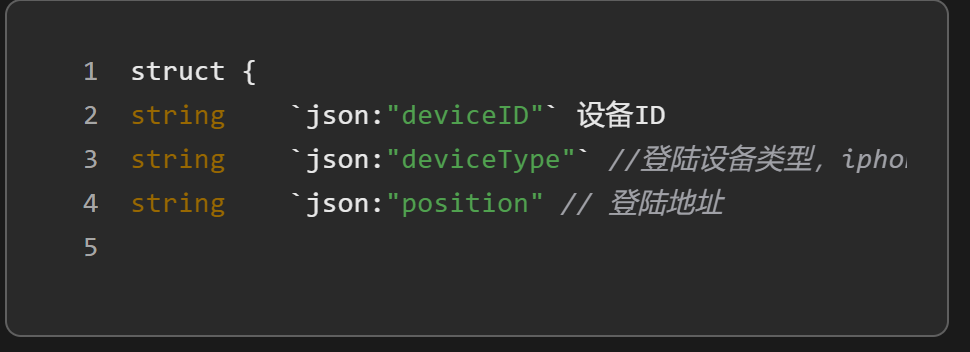
扫码后的编码

临时关联的token,进行记录用户头像信息
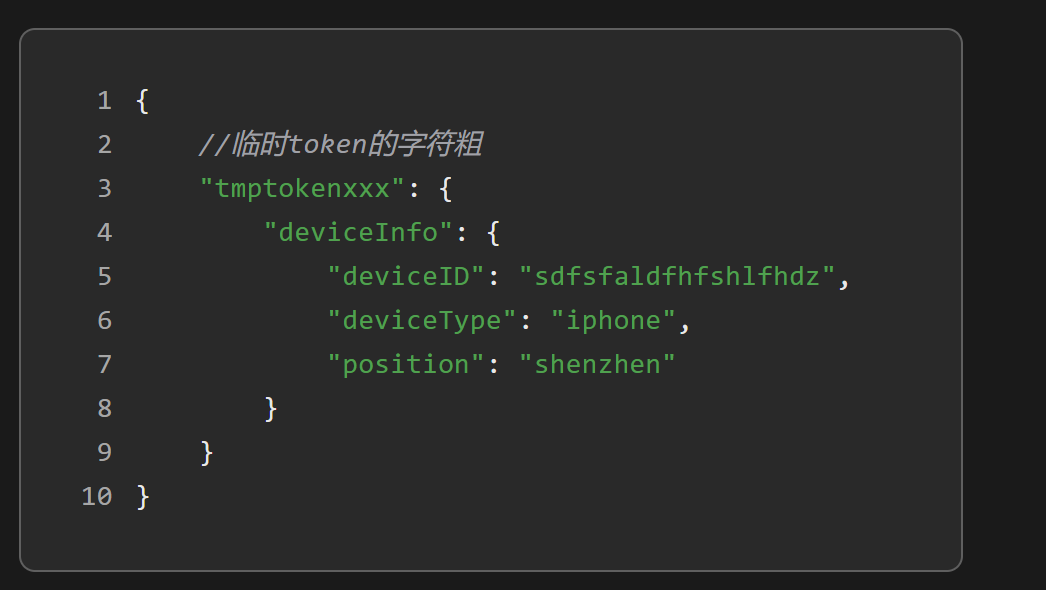
最后更新状态为已经扫码的3
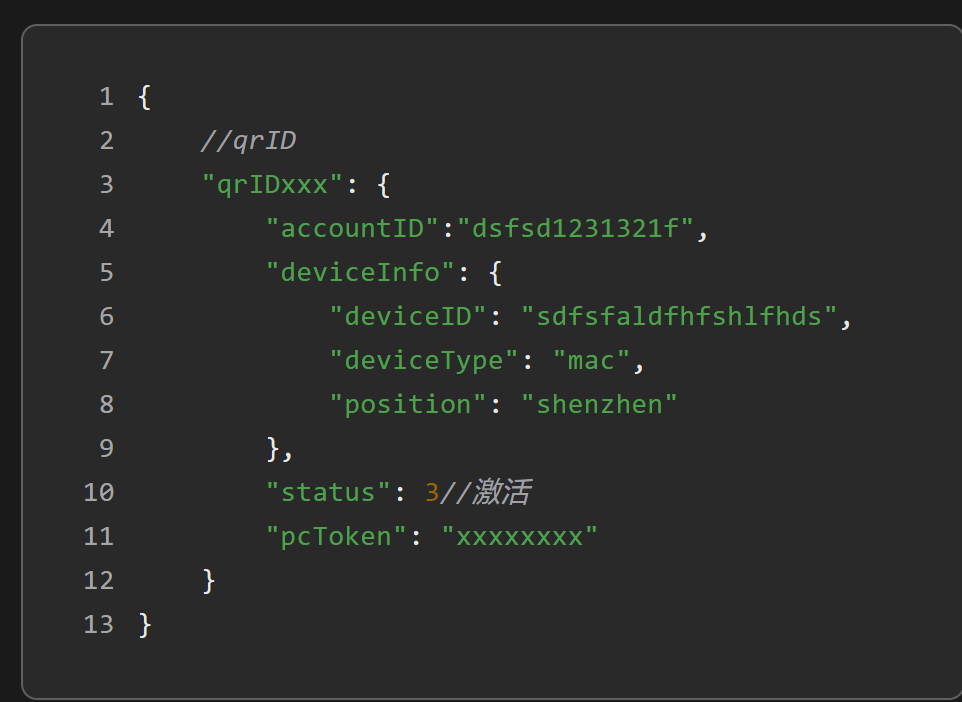
:::info
为什么需要使用临时token,避免扫一下就登录,直接扣钱,太尴尬
:::
技术服务
相当于点赞服务
c需求对齐
业务流程,qps,难点,精准度
- 登录进去
- 看到好的就进行点赞
- 点赞结束,统计点赞次数
a服务
主要是服务模块,一个计数,还有一个网关
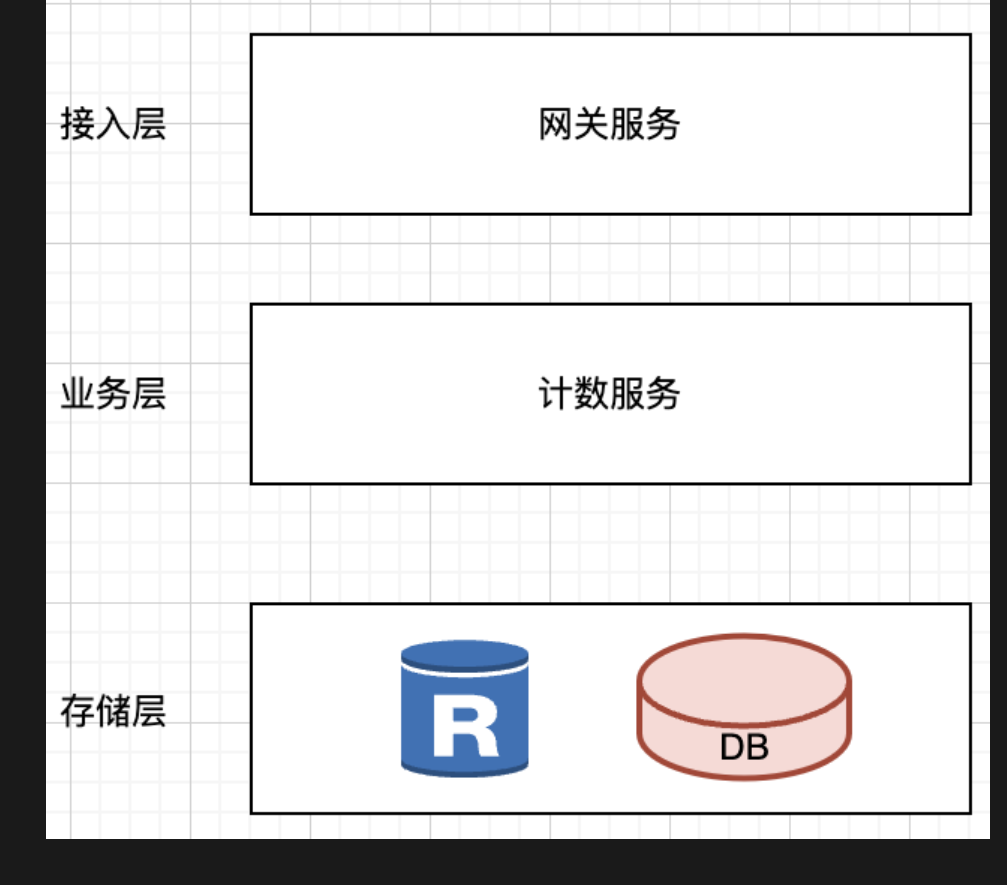
存储设计,redis还有mysql
使用redis作为cache提前返回
mysql,一个博文id点赞次数

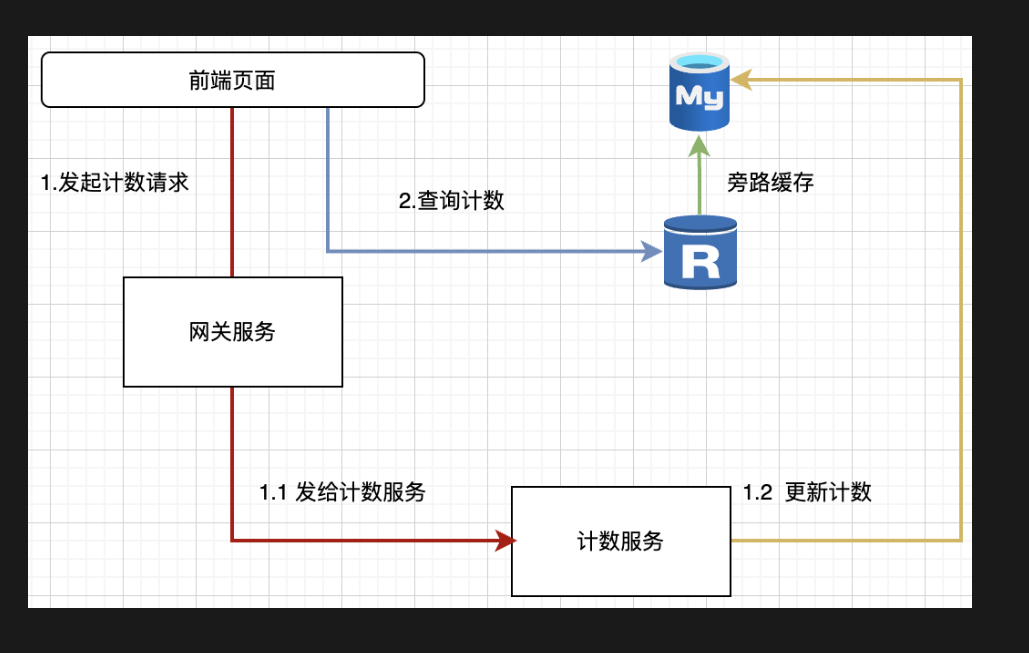
要点分析
数据存放,多行数据,id与action绑定,一个id对应点赞,对应观看
异步操作:通过归并请求才会给你答案,一次次加1,等于一次加n
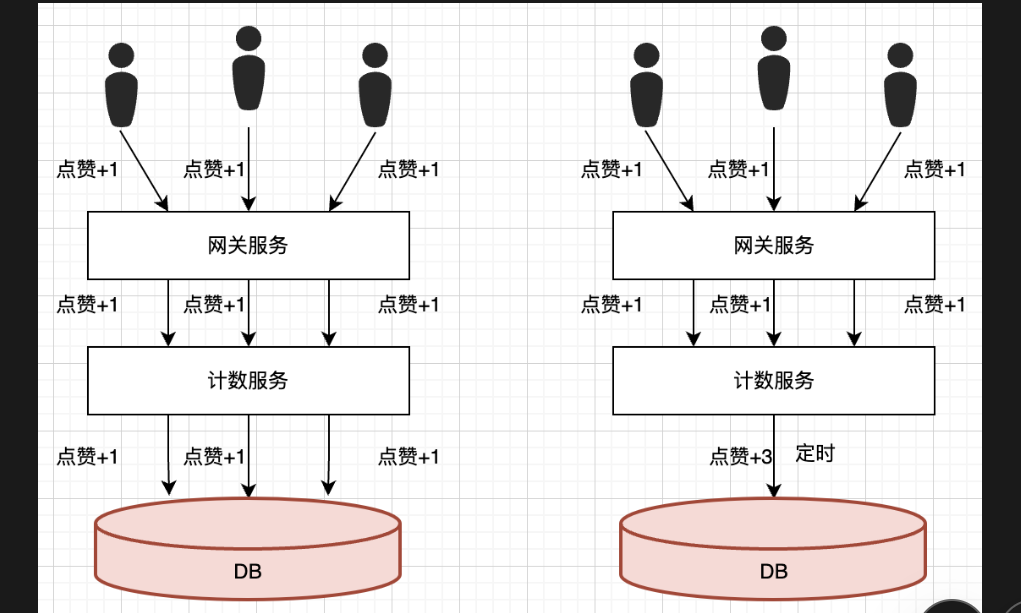
精准度问题
少点赞了,多点赞了其他人的,通过加记录,唯一记录,countrecord

这个就是可以写abcd-105,用户对应的点赞的博文
短链系统设计
c沟通
询问qps,业务流程,难点
请求量对齐:普通的qps
设计对齐:一一对齐,长时间不使用不会消失
架构对齐
服务:转换服务,encoder,decoder,重定向301
storage:两个索引:一个短的,一个长的
要点展开
使用302重定向,生成算法base62,全局唯一id,需要将url编码为一个整数,对应的是自增id,使用雪花,uuid

scale:进行优化
- 使用cdn提高查询速度
- redis进行缓存
数据进行优化:水平拆分(分库分表)
sharding key,使用id来进行
总结
主要是encoder还有的从的人来作为难点,使用base62,但是要全局id,使用唯一uuid
订单系统实现
c需求对齐
qps,业务流程,难点
流程:进行购物车选择购物,创建订单,支付订单,确认收获
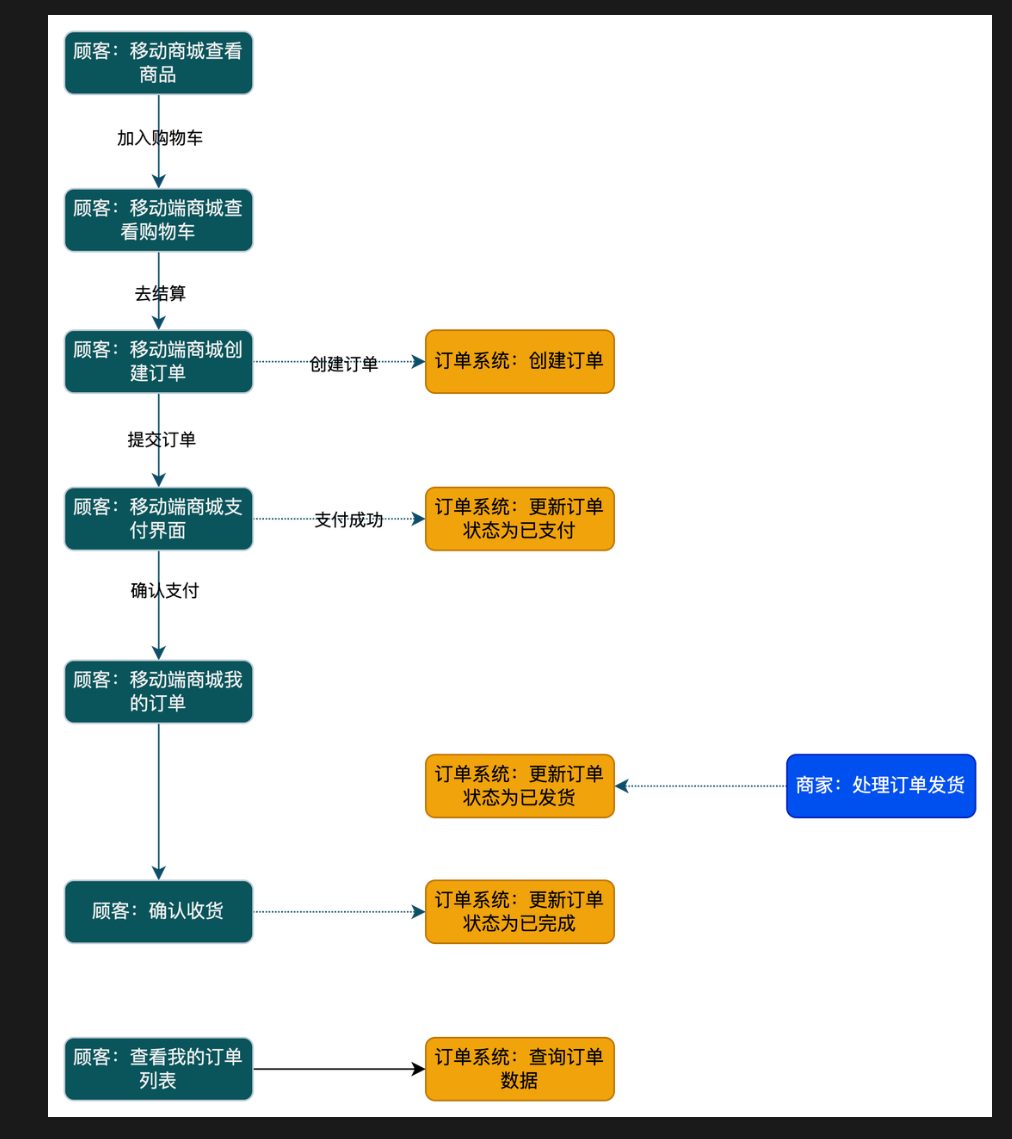
订单:创建
支付:支付失败,超时支付,支付成功
发货:超时发货提醒
qps:直接拉倒100w
高精准:是否运行超卖还有少买《主从同步时延,订单丢失,没有兜底
架构实现
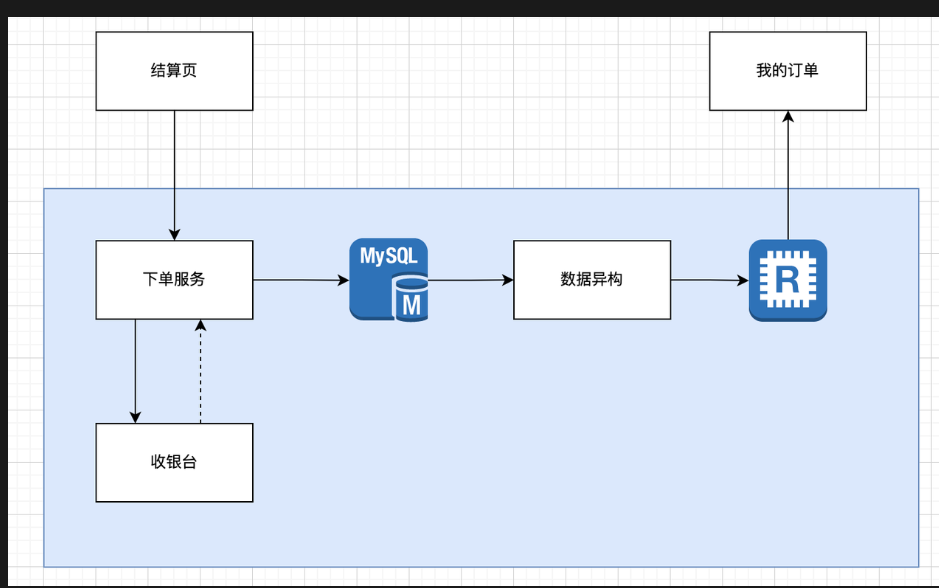
要点分析
storage:核心使用mysql,我的订单列表,使用redis的list可以获取
高精准如何确保:使用状态机模型,先定义好状态,自动售卖机逻辑一样,整个流程基本都是同步,除了发送通知是异步,其余都是正确的
系统设计
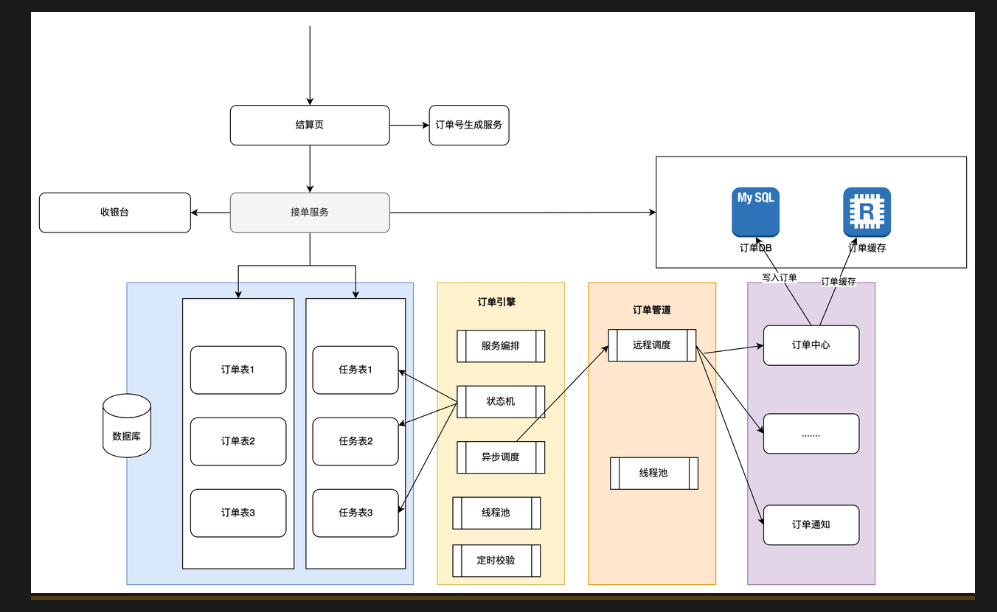
订单下单服务
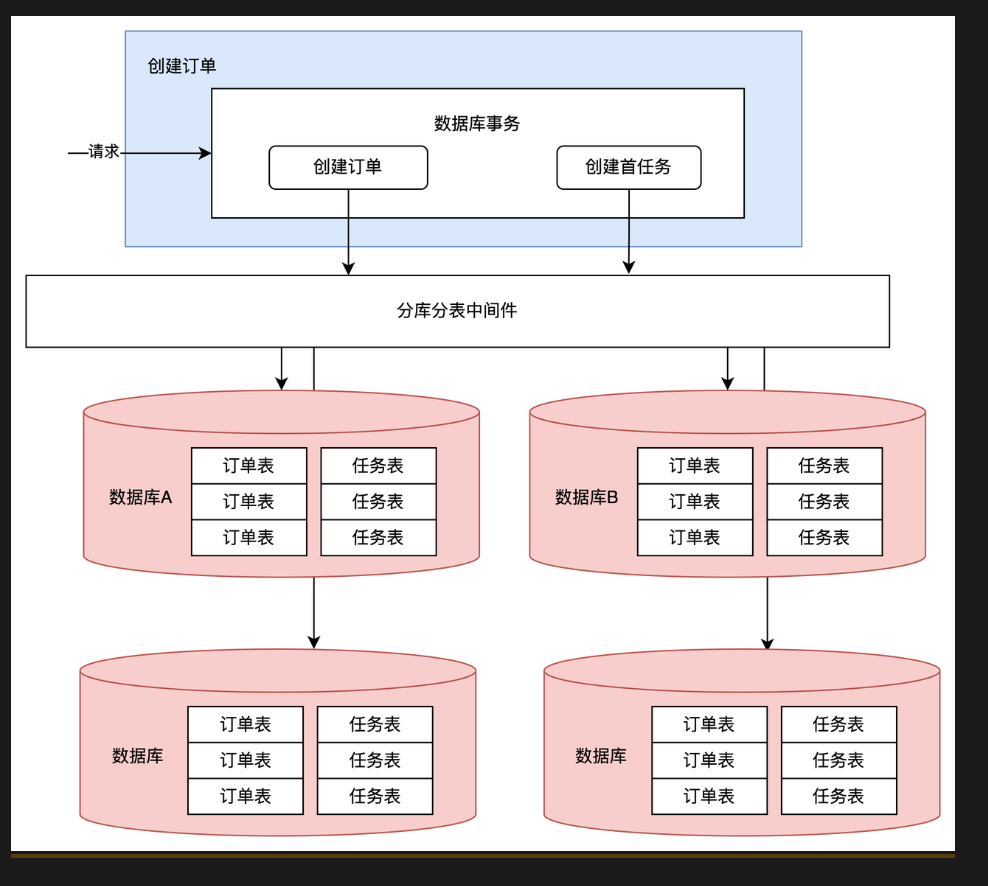
创建订单,需要分库分销sharding
- 任务创建,生成任务,后续使用插入到第二个队列和async一样,失败就是重试
- 异步调用
- 状态机处理,失败任务,多次失败就进行降级
- 幂等性,插入到redis这样,回首先查询不存在,然后再次进行校验
游戏排行榜设计
传统的排行榜系统,使用redis,进行zset来获取zarrange
通过分数+时间戳作为联合分数,这样可以进行排序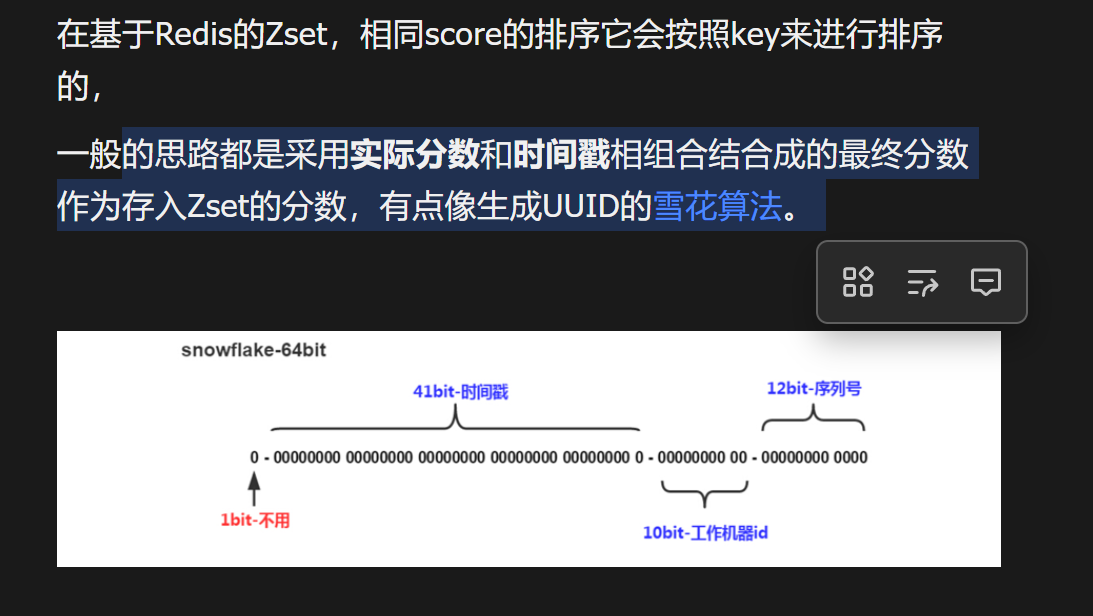
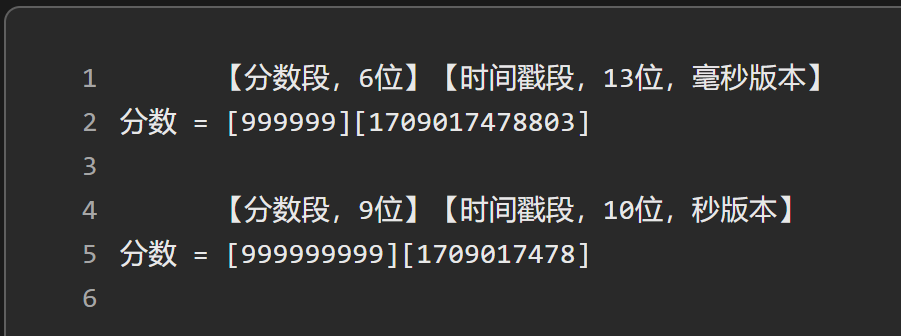
海量数据下的排行榜
区间划分:每一个分数,一个区间

只需要钱k个的
使用heap就可以
当用户信息变更,排行榜下次生成的时候写入,
排序结果生成就返回用户信息
试试查询,那就是轮训就可以,通过zrevrank放入member 还有id来获取
1 | import redis |

