
海量数据题目
所谓海量数据处理就是在大数据情况下来处理具体情况就是内存有限,数据太大无法处理完成所有,因此需要使用特殊处理。
常见的方案就是
- 时间换空间,使用bitmap,哈希,trie树灯解决
- 空间换时间,进行hash到小文件,然后统计小文之后归并统计
常见的方案
- 分治
- 外排序
- 划分
- bitmap
- trie树
- 倒排序
分治方案
顾名思义:就是数据量太多,无法一次性装入到内存,就会hash小文件,统计小文件的
统计访问最多的ip地址

题解:
- 使用hash取模1000,分到1000小文件
- 之后维护一个hashmap来计算频率,可以得到前1000个最大的ip
- 然后使用快排或者使用堆排序
统计300w里面的热门10个查询

大约只有300w个有效,然后就是计算长度300*1k/4=0.75G,可以直接丢到内存进行处理结果
- 使用hash进行计算ip对应的值
- 然后直接堆排序,是Nlogk
有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词
2^30/2^4 = 2^26
2^20/2^4=2^16
26-16=10,计算得到1024个小文件丢入到

海量数据在100台电脑上,统计出 前10个
这个和maoreduce操作差不多,首先就是对当前的电脑进行map,之后把所有的值,之后对每一个key进行映射到新的文件里面,这个是merge操作,最后就是排序操作

还有一个方法1,是所有的元素相同的都在一个机器,直接使用堆排序生成结果。
- 对每一个电脑的进行排序
- 然后进行堆排序
每个文件都看了有query重复,10个文件,每个1g

直接参照上面的解法1MapReduce,进行映射,然后统计,排序
找出共有的url地址
共有的一半可以使用同一个hash函数,都会映射到同一个文件,然后每一个a1,b1进行这样比较

100万里面100的数量
- 使用力扣题目思想,进行淘汰局部队列
- 或者快排思想,计算左边有100个了的值
- 最后就是一个堆排序

外部排序
外部排序就是,分隔号文件之后,然后进行把这个文件排好序,最终使用多路归并排序。
- 分为a1,2,3,4
- 对a1,2,3,4进行排好序
- 现在就是使用归并排序,得到一个完整的
给定10的7文件进行排序
直接使用bitmap,有20个bit,然后输入设置为1,之后输出有1的,如果文件太大,那就是分批来进行解决。
解法二:多路归并
诚然,在面对本题时,还可以通过计算分析出可以用如2的位图法
解决,但实际上,很多的时候,我们都面临着这样一个问题,文
件太大,无法一次性放入内存中计算处理,那这个时候咋办呢?
分而治之,大而化小,也就是把整个大文件分为若干大小的几
块,然后分别对每一块进行排序,最后完成整个过程的排序。k趟
算法可以在kn的时间开销内和n/k的空间开销内完成对最多n个小
于n的无重复正整数的排序。
比如可分为2块(k=2,1趟反正占用的内存只有1.25/2M)
1w4999999和5000000w9999999。
先遍历一趟,首先排序处理1w4999999之间的整数(用
5000000/8=625000个字的存储空间来排序0~4999999之间的整
数),然后再第二趟,对50000011000000之间的整数进行排序
处理。
多层划分
按区间划分处理1-100,101-200
2.5个数找出不重复的
进行区间划分4个厚,然后使用bitmap,首先第一次读取是1,再一次读取就是0,直接输出所有的1
分析:有点像鸽巢原理,整数个数为232,也就是我们可以将这
232个数,划分为28个区域(比如用单个文件代表一个区域),
然后将数据分离到不同的区域,然后不同的区域在利用bitmap就
可以直接解决了。也就是说只要有足够的磁盘空间,就可以很方
便的解决。
5亿个数,找出中位数
区间划分,之后统计个数,使用数学计算中位数在哪一个区间,还有指引。

Bitmap
上面的找出重复的数,可以使用双位bitmap,00没出现,01出现1次,10出现多次,11,没意义
字典树
10w个单词,判断单词是否存在
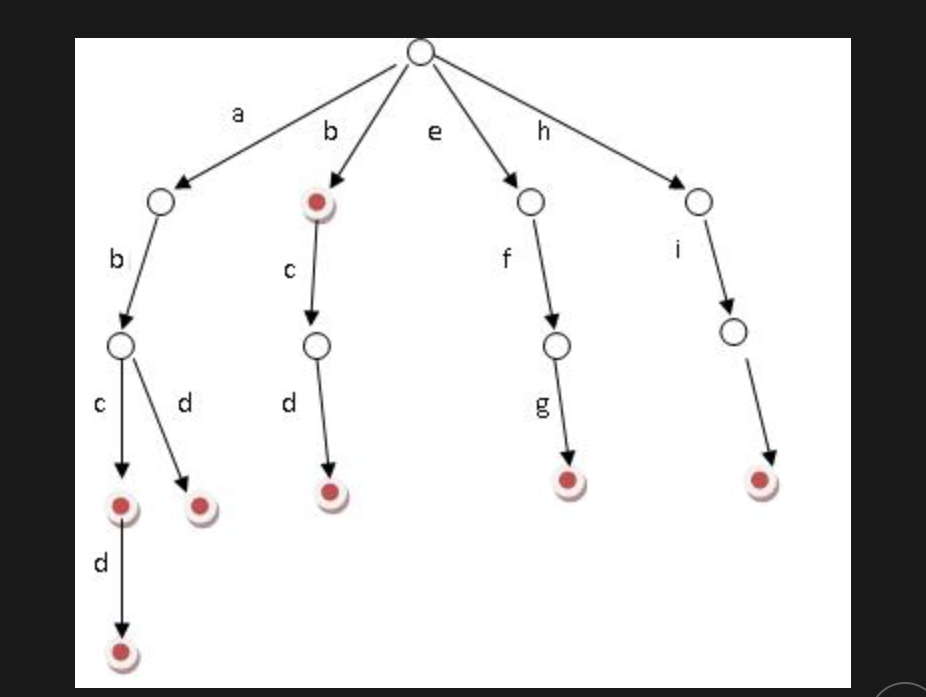
倒排序
es,使用的方案,学术论文查询,根据关键词查出论文

