const ( Follower Role = "follower" Candidate Role = "candidate" Leader Role = "leader" )
设置超时的时间ttl
1 2 3 4 5 6 7
// setting the const of lower bound and upper bound of election time out const ( electionTimeoutMin time.Duration = 250 * time.Millisecond electionTimeOutMax time.Duration = 400 * time.Millisecond // the interval of the log replication replicateInterval time.Duration = 200 * time.Millisecond )
设置关于超时的函数,是否超时,重新开始时钟
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// reset the election time out func(rf *Raft) resetElectionTimeLocked() { // obtain a random election time out // plus the current time rf.electionStart = time.Now() randRange := int64(electionTimeOutMax - electionTimeoutMin) rf.electionTimeOut = electionTimeoutMin + time.Duration(rand.Int63()%randRange) }
// check the election time out func(rf *Raft) isElectionTimeOutLocked() bool { // just check the election time out is out of time return time.Since(rf.electionStart) > rf.electionTimeOut }
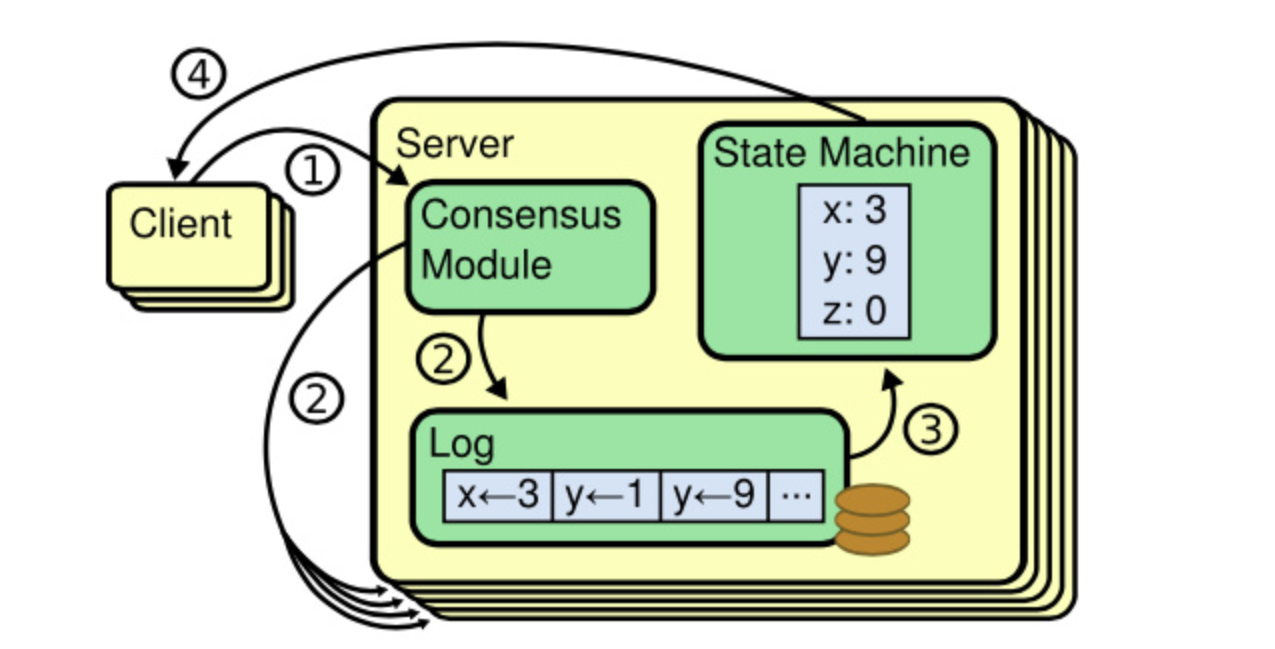
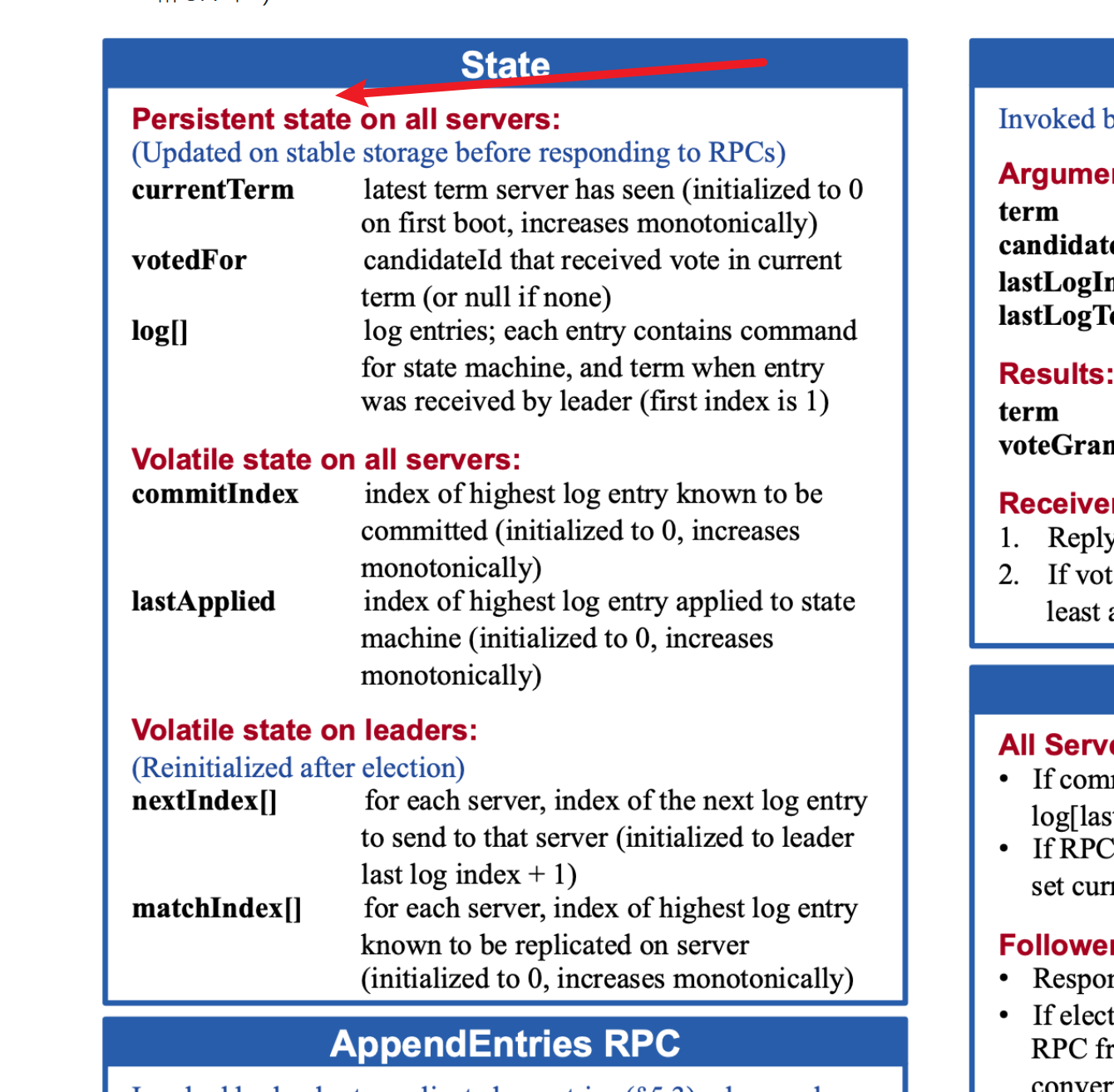
定义raft的数据结构,参考图
currentterm当前的任期
votedfor选举的是谁,使用-1代表没有进行选举
超时时间还有开始时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int// this peer's index into peers[] dead int32// set by Kill() // 添加的数据结构,定义什么时候开始选举的,还有超时时间 role Role currentTerm int votedFor int//vote who (-1 present null) electionStart time.Time electionTimeOut time.Duration // Your data here (PartA, PartB, PartC). // add yourself struct // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain.
}
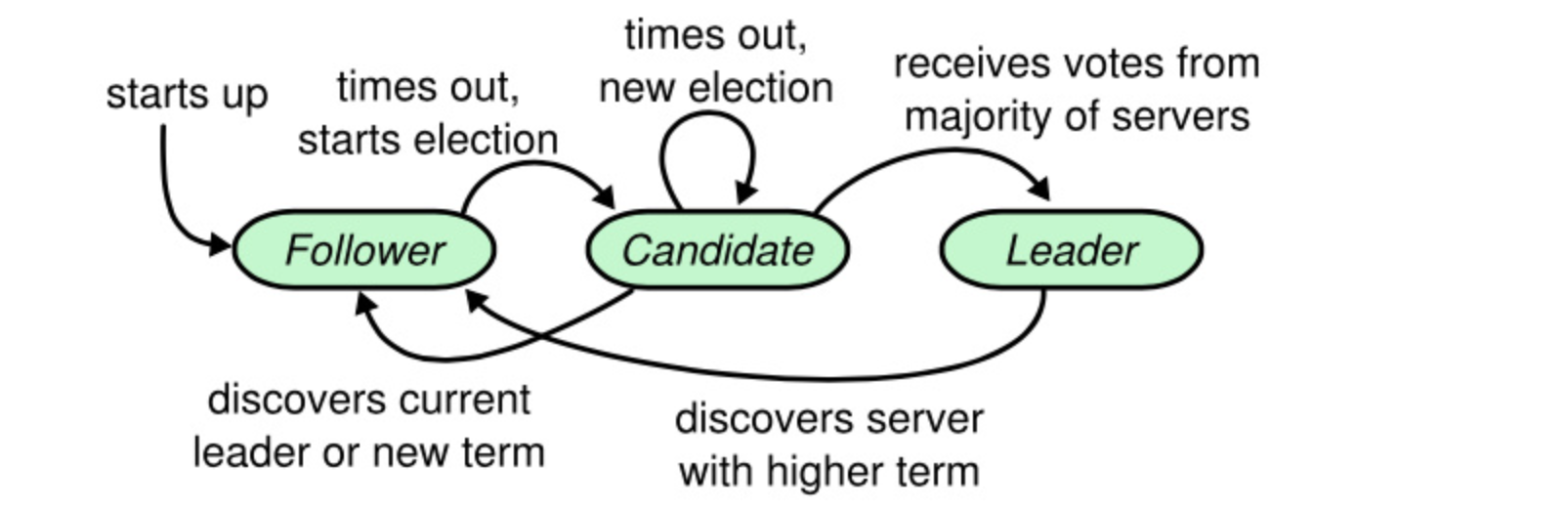
实现become函数
变成follower
重设时钟
更新term,设置角色为follower,并且设置为没有进行选举
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
func(rf *Raft) becomeFollowerLocked(term int) { // compare term ,if term is lower than rf.term ,do not change if rf.currentTerm > term { // add log LOG(rf.me, rf.currentTerm, DError, "Can't become Follower, lower term: T%d", term) return } // log LOG(rf.me, rf.currentTerm, DLog, "%s->Follower, For T%v->T%v", rf.role, rf.currentTerm, term) rf.role = Follower if rf.currentTerm < term { rf.votedFor = -1 } rf.currentTerm = term // all term
}
变成candidate
自己是leader就不用变了(变成candidate就是为了变成leader)
设置角色为candidate,更新votedfor是自己,设置自己currentterm进行加1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
func(rf *Raft) becomeCandidateLocked() { // compare term ,if term is lower than rf.term ,do not change if rf.role == Leader { // add log LOG(rf.me, rf.currentTerm, DError, "Leader can't become Candidate") return } // log LOG(rf.me, rf.currentTerm, DVote, "%s->Candidate, For T%d", rf.role, rf.currentTerm+1) rf.role = Candidate // 选举人的任期+1,并且投票自己 rf.currentTerm++ rf.votedFor = rf.me // me 代表序号 // all term
}
变成leader
只有candidate才可以变成leader
1 2 3 4 5 6 7 8 9 10 11
func(rf *Raft) becomeLeaderLocked() {
if rf.role != Candidate { LOG(rf.me, rf.currentTerm, DError, "Only Candidate can become Leader") return // } LOG(rf.me, rf.currentTerm, DLeader, "Become Leader in T%d", rf.currentTerm)
func(rf *Raft) electionTicker() { for rf.killed() == false {
// Your code here (PartA) // Check if a leader election should be started.
// here only you are not leader ,you can start election,at the same time // you should check the election time out rf.mu.Lock() if rf.role != Leader && rf.isElectionTimeOutLocked() { rf.becomeCandidateLocked() // according to the term ,send request vote to all the peers // only you term is higher than the other ,you can get the vote go rf.startElection(rf.currentTerm) } rf.mu.Unlock()
// pause for a random amount of time between 50 and 350 // milliseconds. ms := 50 + (rand.Int63() % 300) time.Sleep(time.Duration(ms) * time.Millisecond) } }
func(rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) { // Your code here (PartA, PartB). // this function is to handle the RequestVote RPC,when receive rpc // what should server do rf.mu.Lock() defer rf.mu.Unlock() reply.Term = rf.currentTerm reply.VoteGranted = false // if the term is lower than the current term ,reject the vote if args.Term < rf.currentTerm { LOG(rf.me, rf.currentTerm, DVote, "<- S%d, Reject voted, Higher term, T%d>T%d", args.CandidateID, rf.currentTerm, args.Term) return
} // if the term is higher than the current term ,become follower if args.Term > rf.currentTerm { rf.becomeFollowerLocked(args.Term) } // if the server has voted for other ,reject the vote if rf.votedFor != -1 { LOG(rf.me, rf.currentTerm, DVote, "<- S%d, Reject voted, Already voted to S%d", args.CandidateID, rf.votedFor) return
// build RPC call for each peer ,via peer &args askVoteFromPeer := func(peer int, args *RequestVoteArgs) { // this is client call reply := &RequestVoteReply{} // above code ,given a example to call rpc,just pass arg and reply // return ok ok := rf.sendRequestVote(peer, args, reply) rf.mu.Lock() defer rf.mu.Unlock() // 多线程竞争 if !ok { // rpc failed LOG(rf.me, rf.currentTerm, DDebug, "-> S%d, Ask vote, Lost or error", peer) return } LOG(rf.me, rf.currentTerm, DDebug, "-> S%d, AskVote Reply=", peer)
// if currentTerm is lower than peer,become follower if reply.Term > rf.currentTerm { rf.becomeFollowerLocked(reply.Term) return } // double check current role is Candidate && term is equal if rf.contextLostLocked(Candidate, term) { LOG(rf.me, rf.currentTerm, DVote, "-> S%d, Lost context, abort RequestVoteReply", peer) return } // if vote granted ,vote++ if reply.VoteGranted { vote++ // when half of the peer vote ,become leader if vote > len(rf.peers)/2 { rf.becomeLeaderLocked() // start the leader work,send heartbeat & log replication go rf.replicationTicker(term) } } }
1 2 3 4
func(rf *Raft) contextLostLocked(role Role, term int) bool { return rf.role != role || rf.currentTerm != term
rf.mu.Lock() defer rf.mu.Unlock() if !ok { LOG(rf.me, rf.currentTerm, DLog, "-> S%d, Lost or crashed", peer) return } // align the term if reply.Term > rf.currentTerm { rf.becomeFollowerLocked(reply.Term) return } }
// add log entries according to the ApplyMsg struct type LogEntry struct { Term int CommandValid bool Command interface{} }
// add the fields about log: // PrevLogIndex and PrevLogTerm is used to match the log prefix // Entries is used to append when matched // LeaderCommit tells the follower to update its own commitIndex type AppendEntriesArgs struct { Term int LeaderId int
PrevLogIndex int PrevLogTerm int Entries []LogEntry }
type AppendEntriesReply struct { Term int Success bool }
rf.mu.Lock() defer rf.mu.Unlock() if !ok { LOG(rf.me, rf.currentTerm, DLog, "-> S%d, Lost or crashed", peer) return }
// align the term if reply.Term > rf.currentTerm { rf.becomeFollowerLocked(reply.Term) return }
// probe the lower index if the prev log not matched if !reply.Success { idx := rf.nextIndex[peer] - 1 term := rf.log[idx].Term for idx > 0 && rf.log[idx].Term == term { idx-- } rf.nextIndex[peer] = idx + 1 LOG(rf.me, rf.currentTerm, DLog, "Log not matched in %d, Update next=%d", args.PrevLogIndex, rf.nextIndex[peer]) return }
// update the match/next index if log appended successfully rf.matchIndex[peer] = args.PrevLogIndex + len(args.Entries) rf.nextIndex[peer] = rf.matchIndex[peer] + 1
// TODO: need compute the new commitIndex here, // but we leave it to the other chapter }
rf.mu.Lock() defer rf.mu.Unlock() if !ok { LOG(rf.me, rf.currentTerm, DLog, "-> S%d, Lost or crashed", peer) return }
// align the term if reply.Term > rf.currentTerm { rf.becomeFollowerLocked(reply.Term) return }
// probe the lower index if the prev log not matched if !reply.Success { idx := rf.nextIndex[peer] - 1 term := rf.log[idx].Term for idx > 0 && rf.log[idx].Term == term { idx-- } rf.nextIndex[peer] = idx + 1 LOG(rf.me, rf.currentTerm, DLog, "Log not matched in %d, Update next=%d", args.PrevLogIndex, rf.nextIndex[peer]) return }
// update the match/next index if log appended successfully rf.matchIndex[peer] = args.PrevLogIndex + len(args.Entries) rf.nextIndex[peer] = rf.matchIndex[peer] + 1
// TODO: need compute the new commitIndex here, // but we leave it to the other chapter }
rf.mu.Lock() defer rf.mu.Unlock()
if rf.contextLostLocked(Leader, term) { LOG(rf.me, rf.currentTerm, DLog, "Lost Leader[%d] to %s[T%d]", term, rf.role, rf.currentTerm) returnfalse }
// check log, only grante vote when the candidates have more up-to-date log if rf.isMoreUpToDateLocked(args.LastLogIndex,args.LastLogTerm) { LOG(rf.me, rf.currentTerm, DVote, "-> S%d, Reject Vote, S%d's log less up-to-date", args.CandidateId) return }
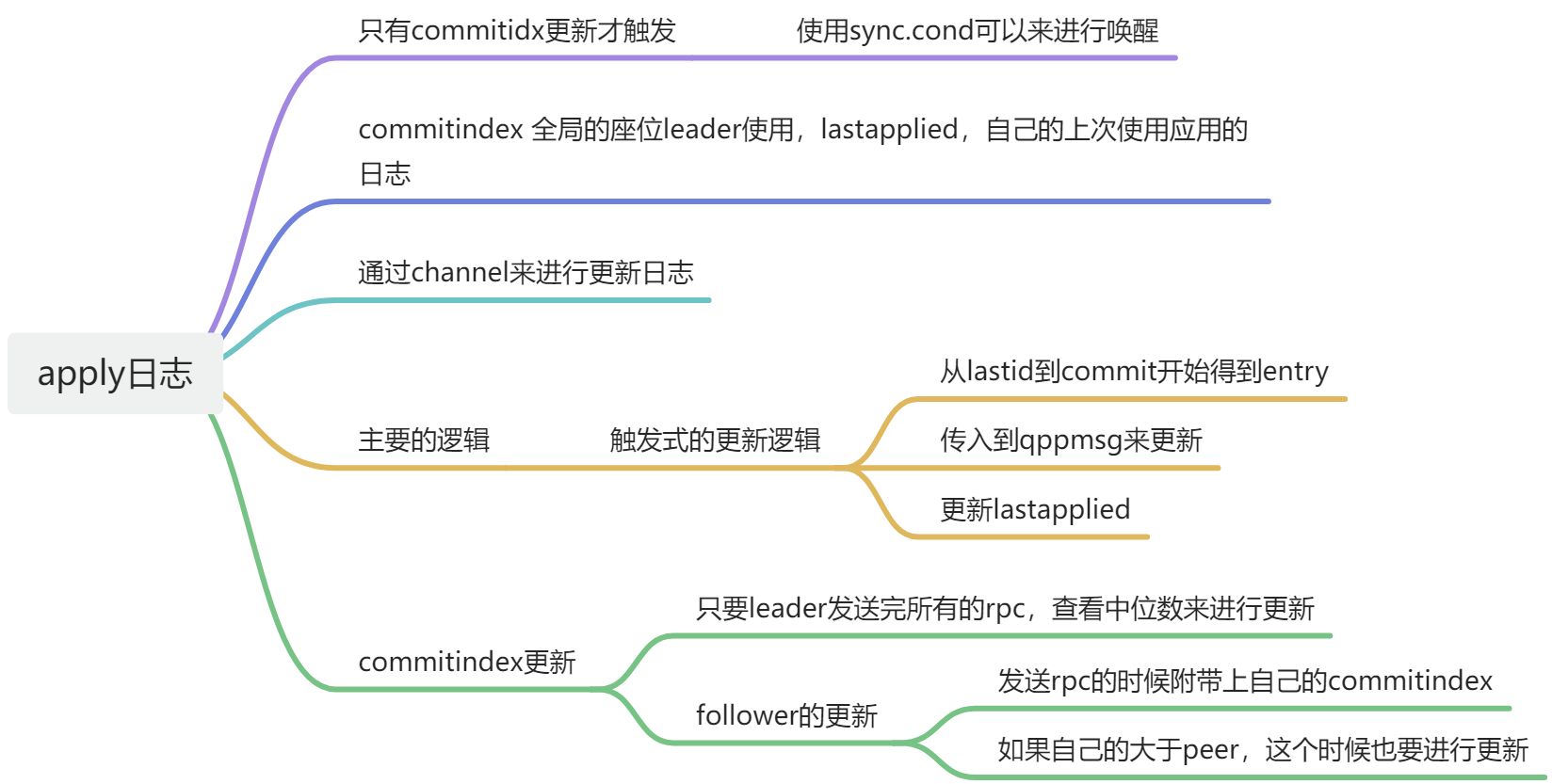
func(rf *Raft) applyTicker() { for !rf.killed() { rf.mu.Lock() rf.applyCond.Wait()
entries := make([]LogEntry, 0) // should start from rf.lastApplied+1 instead of rf.lastApplied for i := rf.lastApplied + 1; i <= rf.commitIndex; i++ { entries = append(entries, rf.log[i]) } rf.mu.Unlock()
for i, entry := range entries { rf.applyCh <- ApplyMsg{ CommandValid: entry.CommandValid, Command: entry.Command, CommandIndex: rf.lastApplied + 1 + i, } }
// update the commmit index if log appended successfully rf.matchIndex[peer] = args.PrevLogIndex + len(args.Entries) rf.nextIndex[peer] = rf.matchIndex[peer] + 1// important: must update majorityMatched := rf.getMajorityIndexLocked() if majorityMatched > rf.commitIndex { LOG(rf.me, rf.currentTerm, DApply, "Leader update the commit index %d->%d", rf.commitIndex, majorityMatched) rf.commitIndex = majorityMatched rf.applyCond.Signal() } }
获取众数的代码
1 2 3 4 5 6 7 8 9
func(rf *Raft) getMajorityIndexLocked() int { // TODO(spw): may could be avoid copying tmpIndexes := make([]int, len(rf.matchIndex)) copy(tmpIndexes, rf.matchIndex) sort.Ints(sort.IntSlice(tmpIndexes)) majorityIdx := (len(tmpIndexes) - 1) / 2 LOG(rf.me, rf.currentTerm, DDebug, "Match index after sort: %v, majority[%d]=%d", tmpIndexes, majorityIdx, tmpIndexes[majorityIdx]) return tmpIndexes[majorityIdx] // min -> max }
对follower更新
在进行rpc调用的时候传入了commitind,如果比peer的大,就是需要更新调用了
1 2 3 4 5 6 7 8 9
// update the commit index if needed and indicate the apply loop to apply if args.LeaderCommit > rf.commitIndex { LOG(rf.me, rf.currentTerm, DApply, "Follower update the commit index %d->%d", rf.commitIndex, args.LeaderCommit) rf.commitIndex = args.LeaderCommit if rf.commitIndex >= len(rf.log) { rf.commitIndex = len(rf.log) - 1 } rf.applyCond.Signal() }
func(rf *Raft) persistLocked() { w := new(bytes.Buffer) e := labgob.NewEncoder(w) e.Encode(rf.currentTerm) e.Encode(rf.votedFor) e.Encode(rf.log) raftstate := w.Bytes() // leave the second parameter nil, will use it in PartD rf.persister.Save(raftstate, nil) }
// --- in raft.go const ( InvalidIndex int = 0 InvalidTerm int = 0 )
为了让代码看着更易懂,我们封装了一个在日志数组中找指定 term 第一条日志的函数<font style="color:rgb(51, 51, 51);background-color:#FFFFFF;">rf.firstLogFor</font>:
1 2 3 4 5 6 7 8 9 10 11
// --- in raft.go func(rf *Raft) firstLogFor(term int) int { for i, entry := range rf.log { if entry.Term == term { return i } elseif entry.Term > term { break } } return InvalidIndex }
由于从前往后,日志的 term 是一段段的单调递增的,则从前往后找,找到第一个满足 term 的日志,就可以返回。如果相关 term 不存在,则返回 <font style="color:rgb(51, 51, 51);background-color:#FFFFFF;">InvalidIndex</font>。