
nlp任务
情感类别分类
整体的思路就是,进行数据清洗,然后设置编码的时候,把fp函数首先经过tokenlization,之后设置label是数据集上的label,然后进行返回。使用分类模型。之后的评估函数是f1还有acc,然后设置trainer
- 读取ds
- 分割ds
- 对数据集使用map进行fp变换
- 设置model
- 之后设置评估acc
- 然后设置trainer
1 | from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments |
命名实体识别
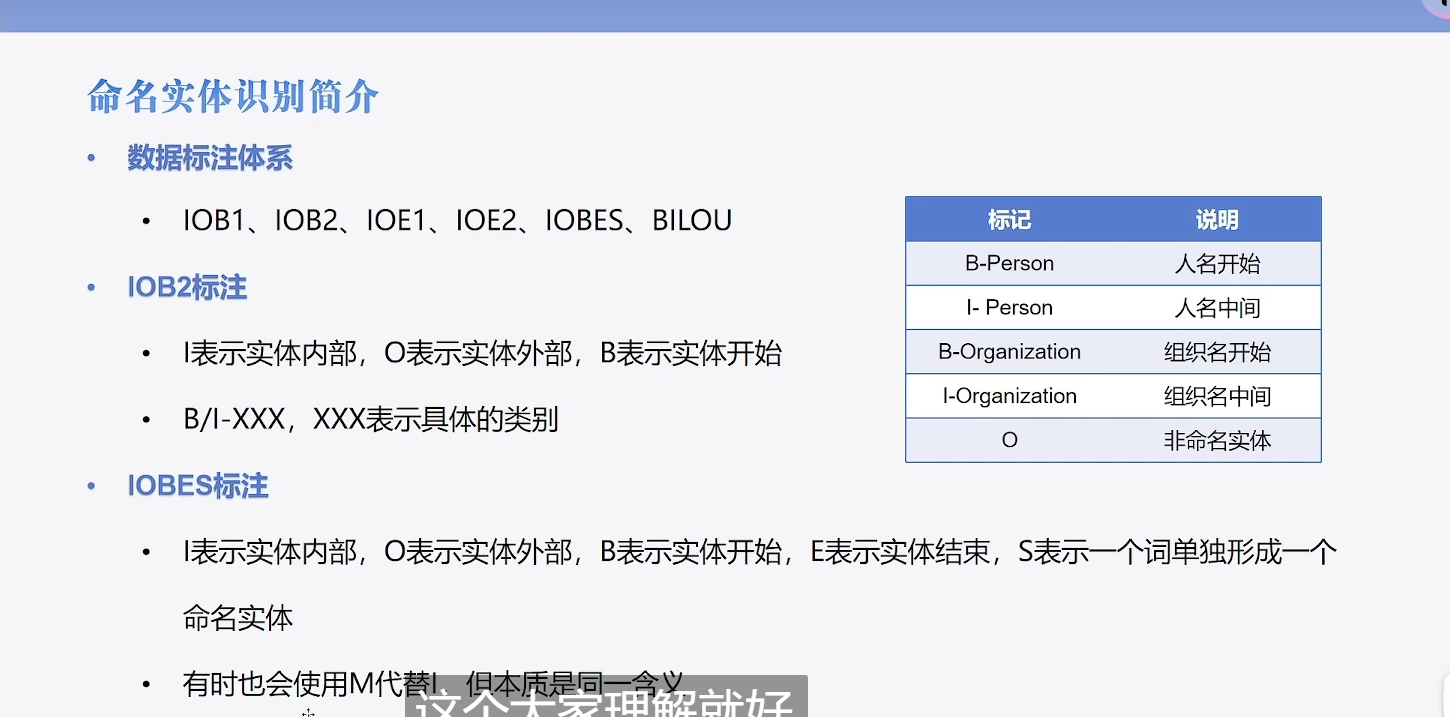

先列出来BIOES分别代表什么意思:
- B,即Begin,表示开始
- I,即Intermediate,表示中间
- E,即End,表示结尾
- S,即Single,表示单个字符
- O,即Other,表示其他,用于标记无关字符
将“小明在北京大学的燕园看了中国男篮的一场比赛”这句话,进行标注,结果就是:
1 | [B-PER,E-PER,O, B-ORG,I-ORG,I-ORG,E-ORG,O,B-LOC,E-LOC,O,O,B-ORG,I-ORG,I-ORG,E-ORG,O,O,O,O] |
通过NER模型,将“小明 ”以PER,“北京大学”以ORG,“燕园”以LOC,“中国男篮”以ORG为类别分别挑了出来。
:::info
这个含义就是说b是开始b-per(人名的开始)e-per(人名的结束),o表示没用的相当于介词
:::
:::color4
这个ner就是开始识别每一个字是什么位置,起什么作用的
:::
dataset模块
ner_datasets[“train”][0]
1 | {'id': '0', |
1 | label_list = ner_datasets["train"].features["ner_tags"].feature.names |
可以看到是每一个word都有一个属性0-6,
fp函数
重点的就是实现fp函数,如何把label进行标注
- 首先通过tokenlization进行编码
- 之后对每一个句子开始进行遍历,放入labels
- 然后设置返回的labels
1 | # 借助word_ids 实现标签映射 |
1 |
|
模型创建
使用的不是二分类任务,这个时候就要制定特定的num
1 | # 对于所有的非二分类任务,切记要指定num_labels,否则就会device错误 |
评估函数
1 | import numpy as np |
trainer设置
直接跳过,参考上一节
完整的代码
1 | import evaluate |
机器阅读
相当于是做阅读理解,这个时候就是下面这种格式
1 | {'id': 'TRAIN_186_QUERY_0', |
:::color4
内容+q+a
:::
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.

