
kafka
为什么需要kafka
kafka也是一种消息队列。
问题引入
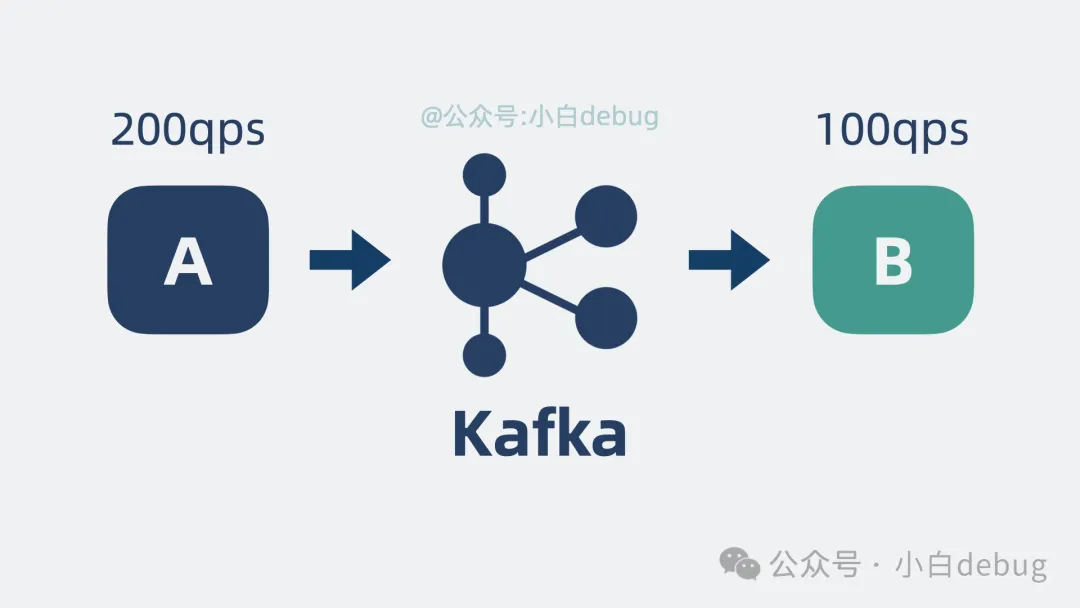
当a服务每次产生200个消息,但是b服务每秒只能处理100个消息,消息处理不过来,就加入一个中间层,那就是kafka
消息队列介绍
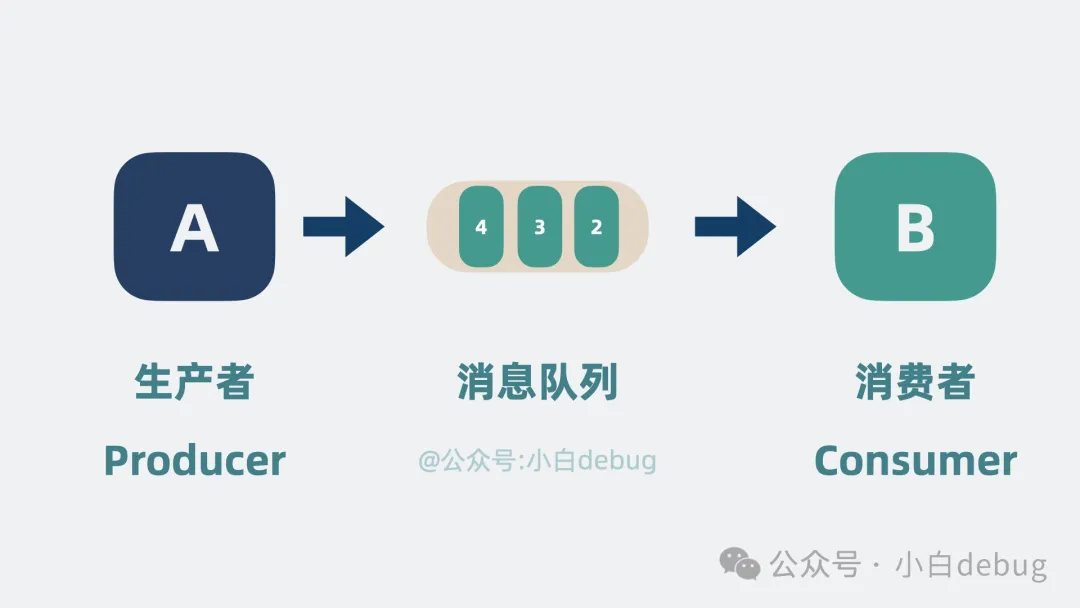
消息队列名称里面包含队列两个字,那他就是一种队列数据结构
高性能
为了能让更多的消费者嫩能够消费消息队列,可以吧一个kafka被多个生产者还有消费者来进行使用
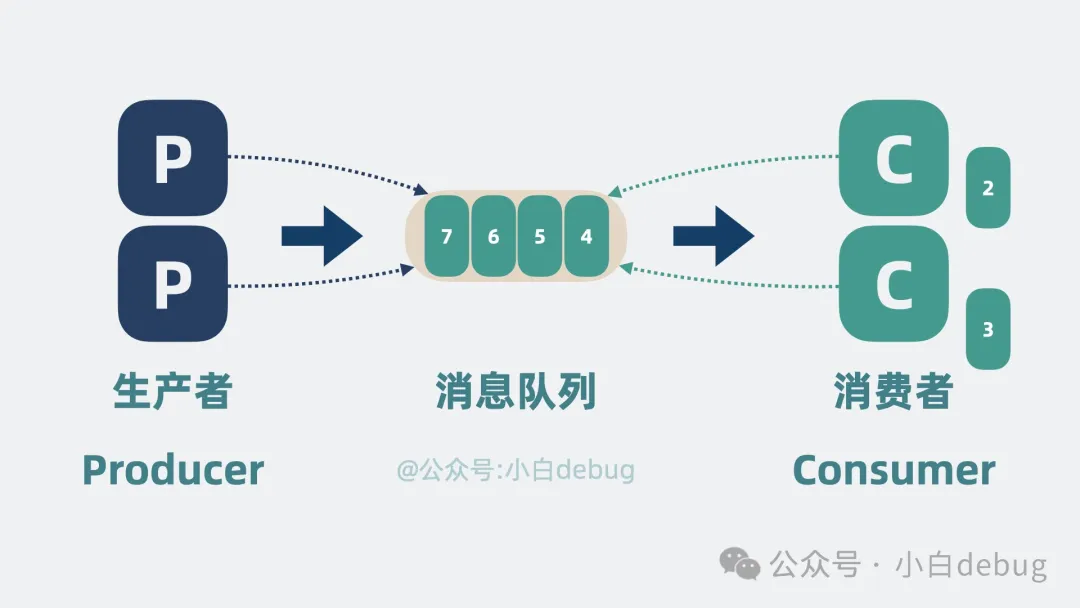
但是会引出一个问题
多个生产者还有消费者抢夺一个消息队列
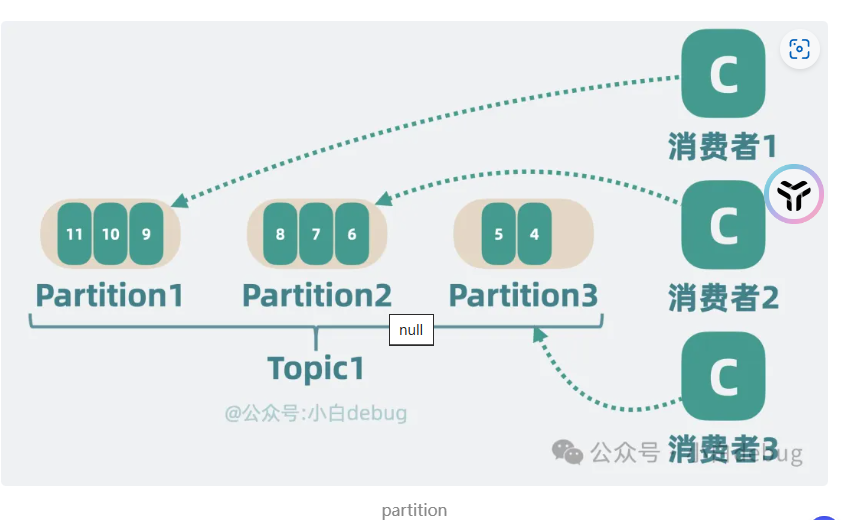
这里可以使用topic来进行表示生产者还有消费者是哪一个主题,选择特定的消息队列来消费
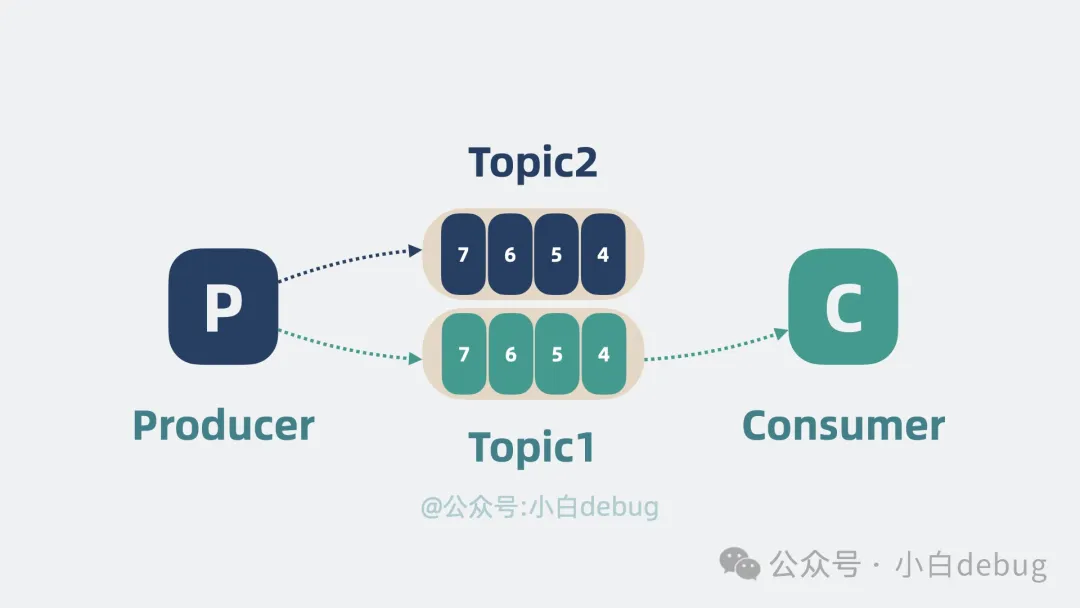
但是一个消息队列的topic还是太多也容易出现争抢问题,这样我们可以对消息队列进行分区,每一个消费者值属于特定的分区(jdk1.7的hashmap思想)
高扩展性
扩展就是进行加机器的意思
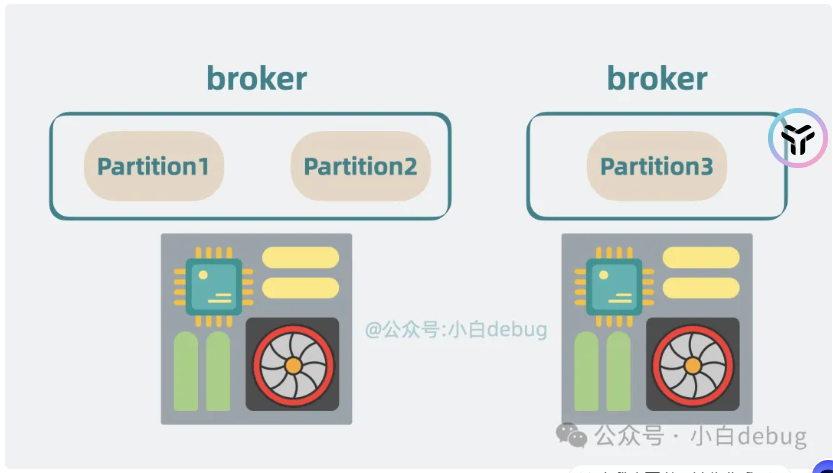
当分区过多在一个机器上,内存可能会爆炸
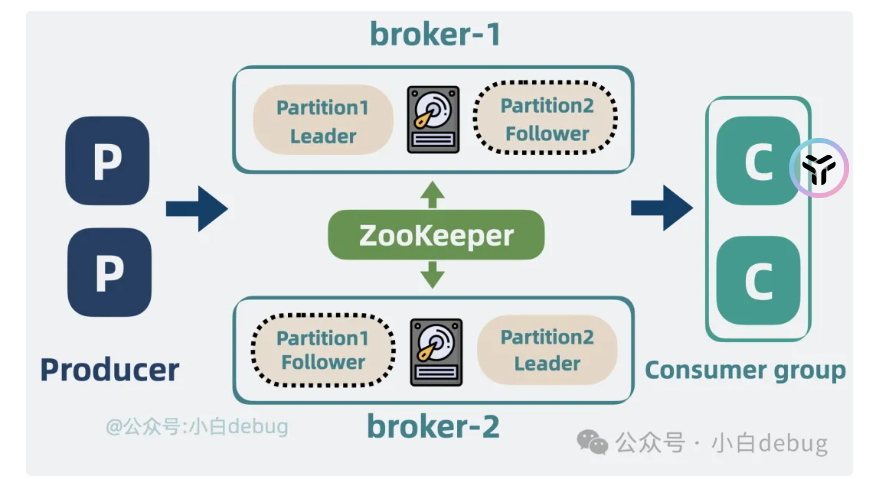
因此可以将分区分散部署到不同的机器上面(分布式),分区的荷载一起交一个broker
高可用性
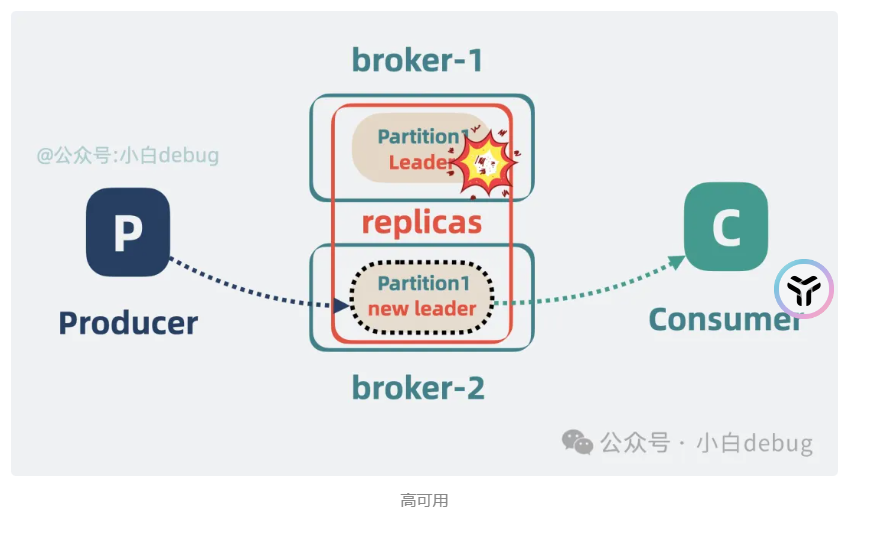
问题:当这个机器的broker全部挂掉,那不就是没有机器可以使用了吗?
多加几个副本,分散到不同的broker上面,使用选举策略来进行选举
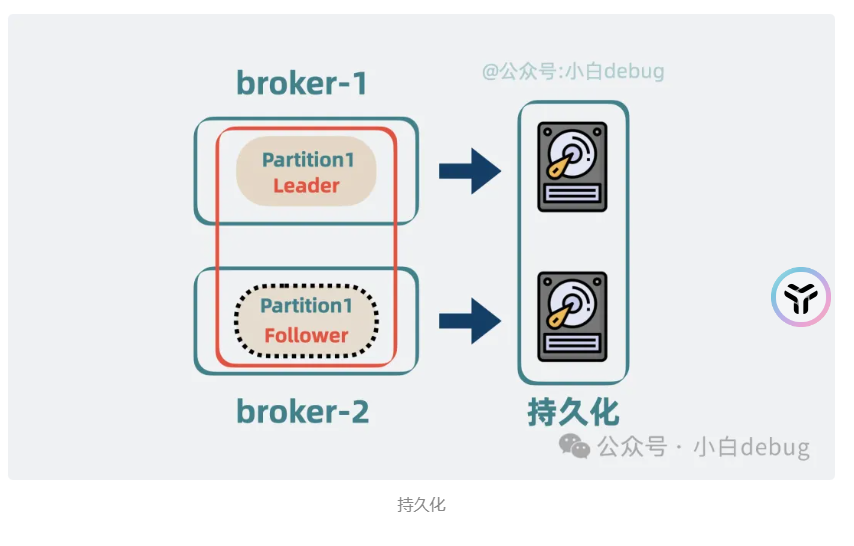
持久化
如果所有的机器全部都挂了,那就是需要存放到本地disk里面。
注册中心
zookerp
主要是为了服务发现,还有进行选举使用,定期与broker来进行沟通,看是否坏了
常见问题
顺序消费
我们知道kafka一个topic对应多个分区,如果要顺序消费,那就是让分区变成,那就是顺序消费
或者是在发送消息制定特定的分区,这样都是一个分区
消息不丢失
生产不丢失
生产是使用kafkatemplate来进行send操作的,可以使用get来进行知道,同时设置retry次数
异步是使用future,可以使用下面的操作
1 | ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o); |
消费不丢失
那就是只有消费完了,然后设置offset为已经消费,而不是一开始就自动提交
kafka弄丢了消息
设置acks=all,这个代表所有的副本全部同步后才叫发送成功
kafka不重复消费
消费不提交的时候,使用手动提交offset出现的问题
做幂等校验。使用mysql主键或者redis的set来进行操作。
kafka重试机制
消费重试
问题引出
当一个消费被卡主,后续的消费会不会卡主
默认的操作就是对异常操作进行重试,如果不行就跳过这个。
最大的重试次数是-1
重试失败后如何进行告警,重写handler
1 |
|
死信队列
当重试过多,会进行跳过,这个时候就会进入到死信队列
@RetryableTopic 是 Spring Kafka 中的一个注解,它用于配置某个 Topic 支持消息重试,更推荐使用这个注解来完成重试。
1 | // 重试 5 次,重试间隔 100 毫秒,最大间隔 1 秒 |
当达到最大重试次数后,如果仍然无法成功处理消息,消息会被发送到对应的死信队列中。对于死信队列的处理,既可以用 @DltHandler 处理,也可以使用 @KafkaListener 重新消费。
著作权归JavaGuide(javaguide.cn)所有 基于MIT协议 原文链接:https://javaguide.cn/high-performance/message-queue/kafka-questions-01.html

