
es
问题引入
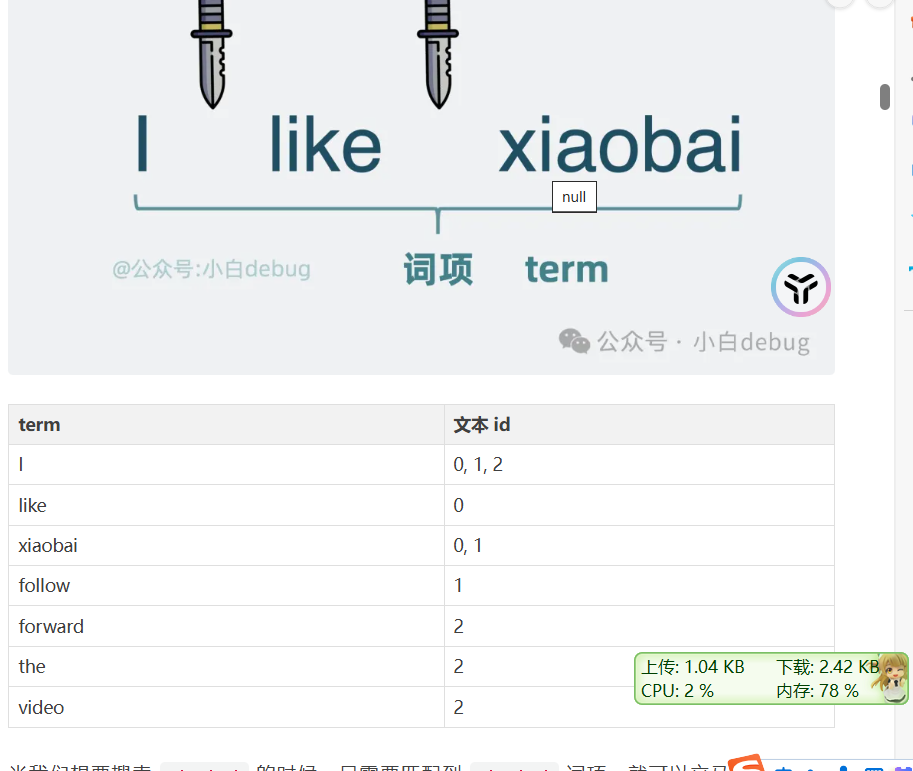
倒排序,就是通过搜索引擎输入关键词,插入出文章,改怎么处理
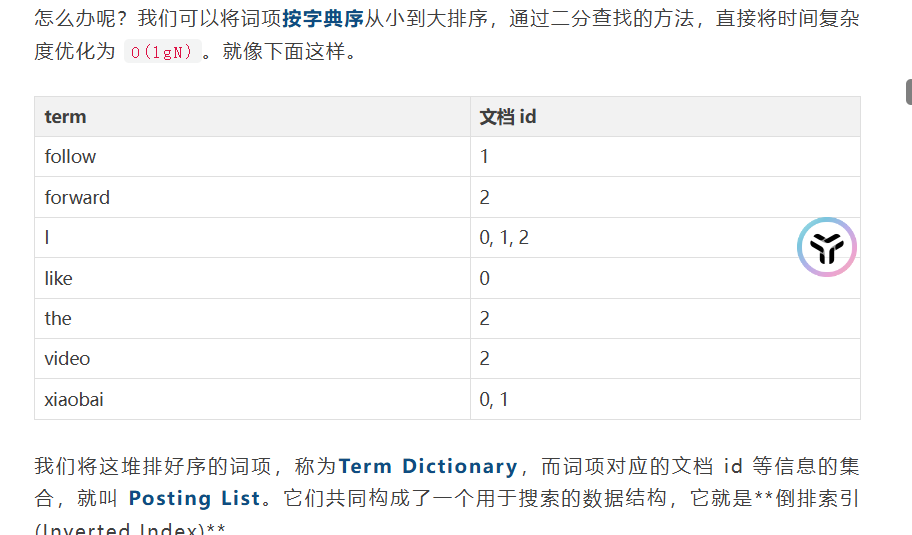
使用倒排索引,就是进行切词,然后根据词语,设置哪些文章出现了这个词语
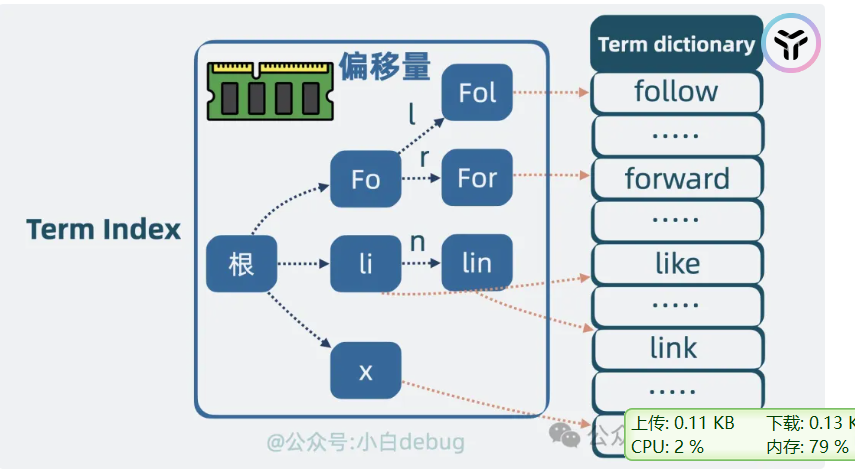
但是这样查询就是ON的复杂度,一个个查询单词,因此可以使用字典树
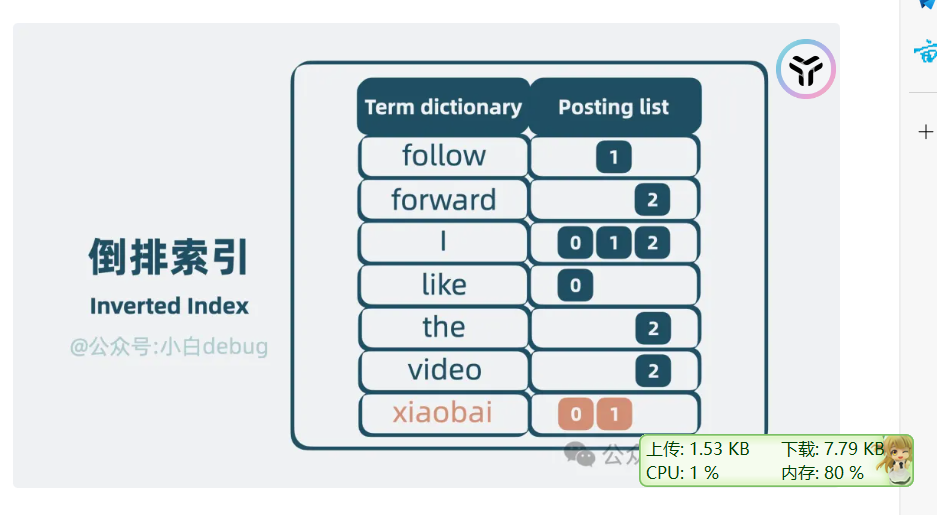
单词+出现的列表就构成了倒排索引
因为数据太大,只能放入到disk里面
term index
数据压缩,有共同的前缀,不需要一个个单词出现
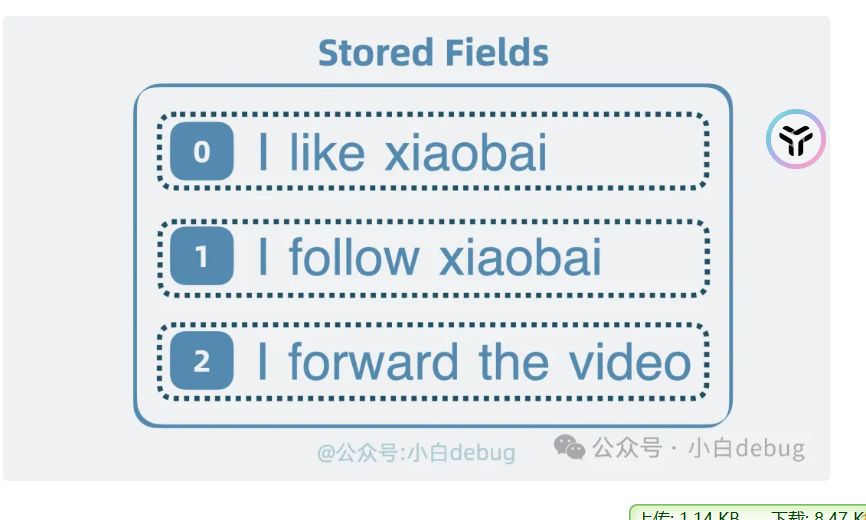
stored fields
之前查询的是文档id,需要id查到内容,存放完整的内容就是stored
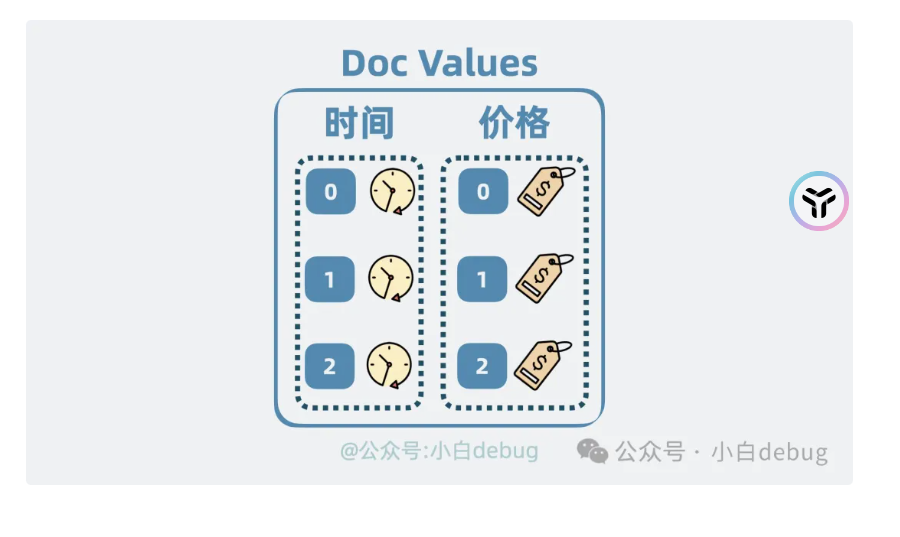
doc value
是将文档id映射到对应的字段,例如文档是一个手机的介绍,他就映射到时间是什么时候产的,价格是多少
segment就是上面的合并
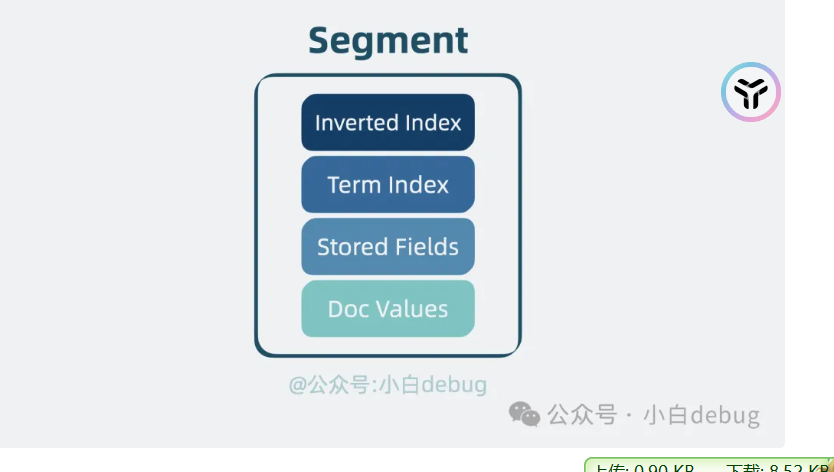
lucene
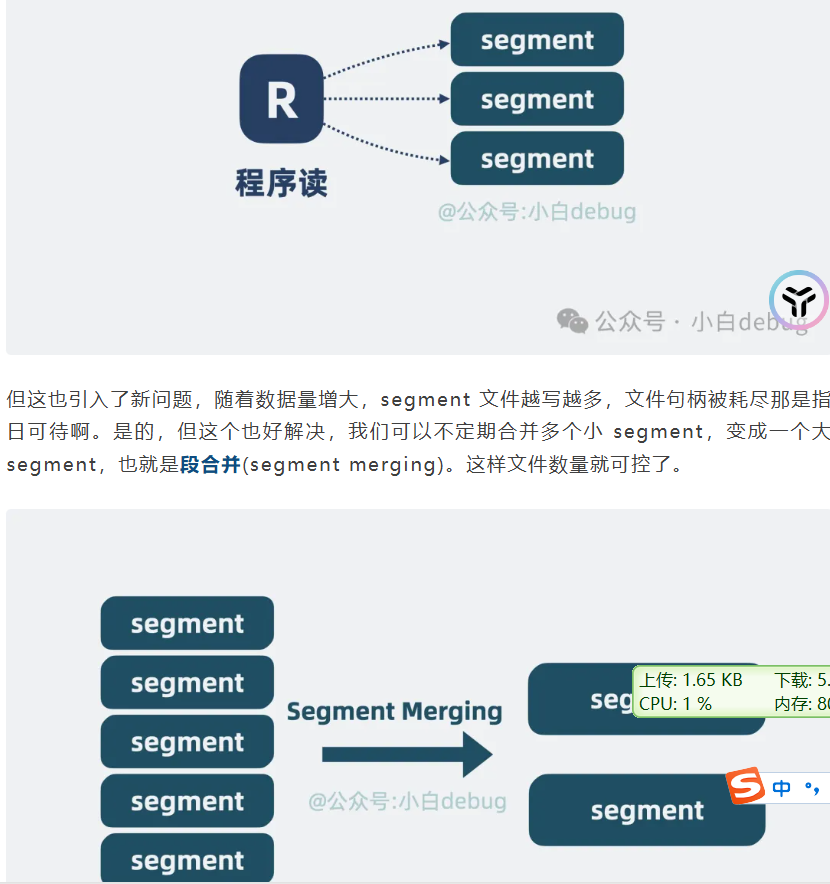 并发读取segment,小的segment定期进行合并
并发读取segment,小的segment定期进行合并
高性能
也是按照之前kafka的思路优化,切分为不同的topic,这里的就是index name1
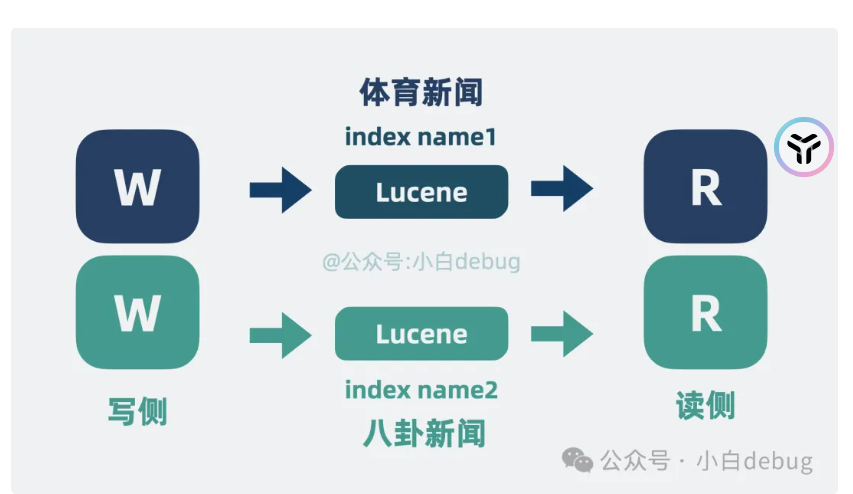
之后再次按照kafka更新的思路,切换为不同分区,这里是叫做shard
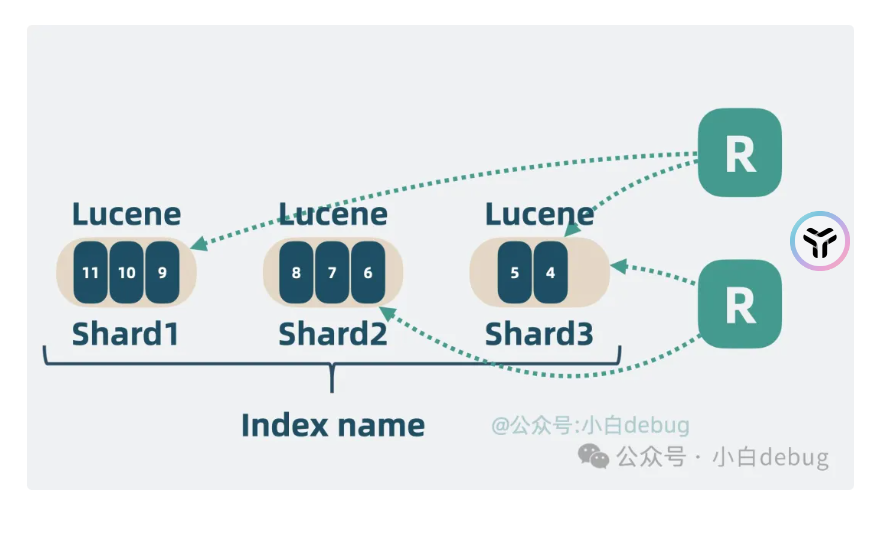
高扩展性
照样参考kafka,这个是broker编程node
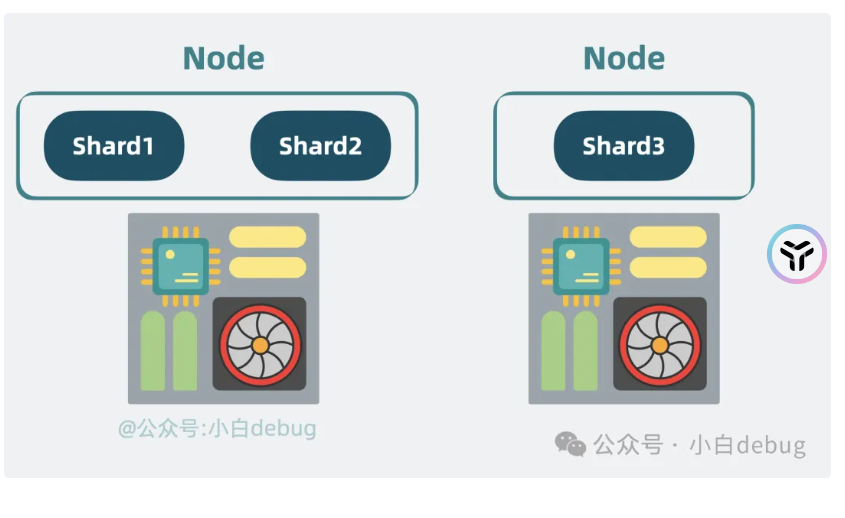
高可用性
参考kafka的leader

node角色化
这个是参考gfs,分为master,数据节点,协调节点
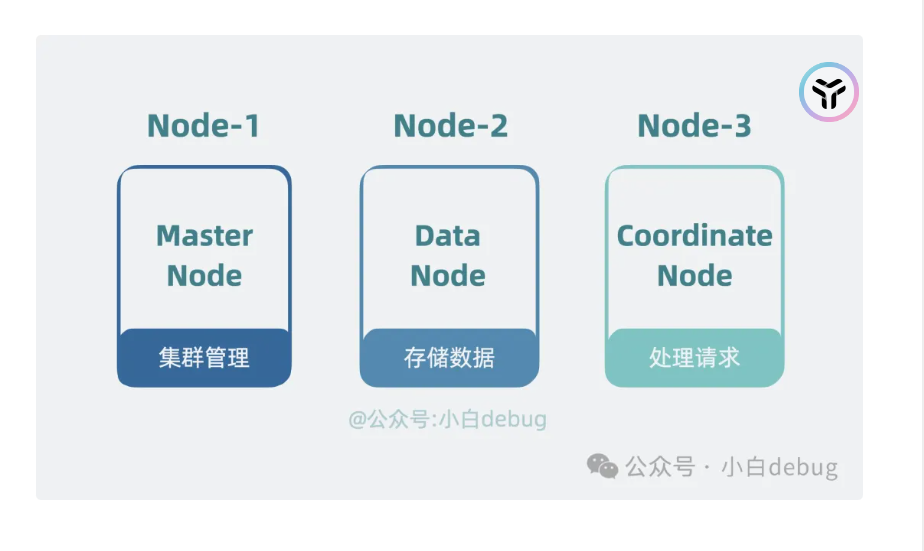 叫主节点(Master Node), 负责存储管理数据的,叫数据节点(Data Node), 负责接受客户端搜索查询请求的叫协调节点(Coordinate Node)。集群规模小的时候,一个 Node 可以同时充当多个角色,随着集群规模变大,可以让一个 Node 一个角色。
叫主节点(Master Node), 负责存储管理数据的,叫数据节点(Data Node), 负责接受客户端搜索查询请求的叫协调节点(Coordinate Node)。集群规模小的时候,一个 Node 可以同时充当多个角色,随着集群规模变大,可以让一个 Node 一个角色。
使用raft来进行去中心化
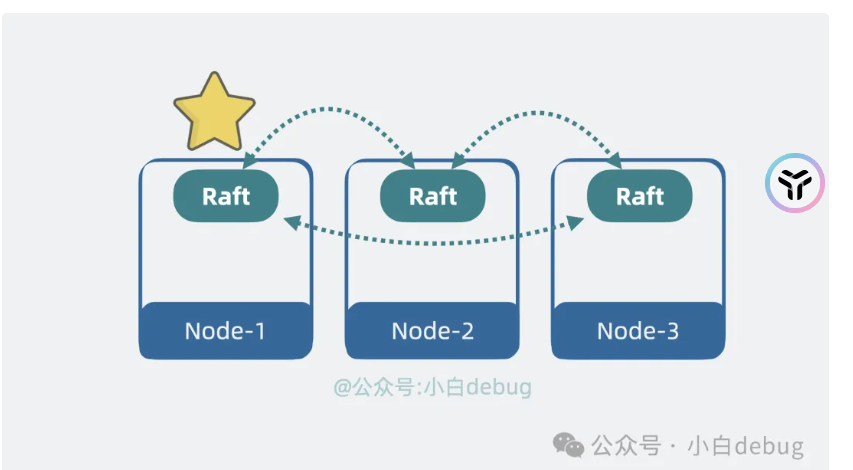
写入流程
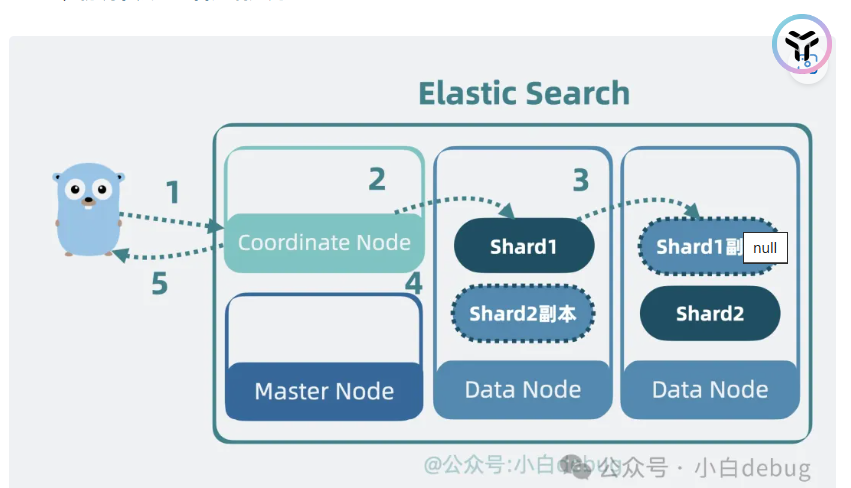
使用协调node,找到对应的data node
写到底层的segment,之后进行同步shard
然后发送ack代表写入ok
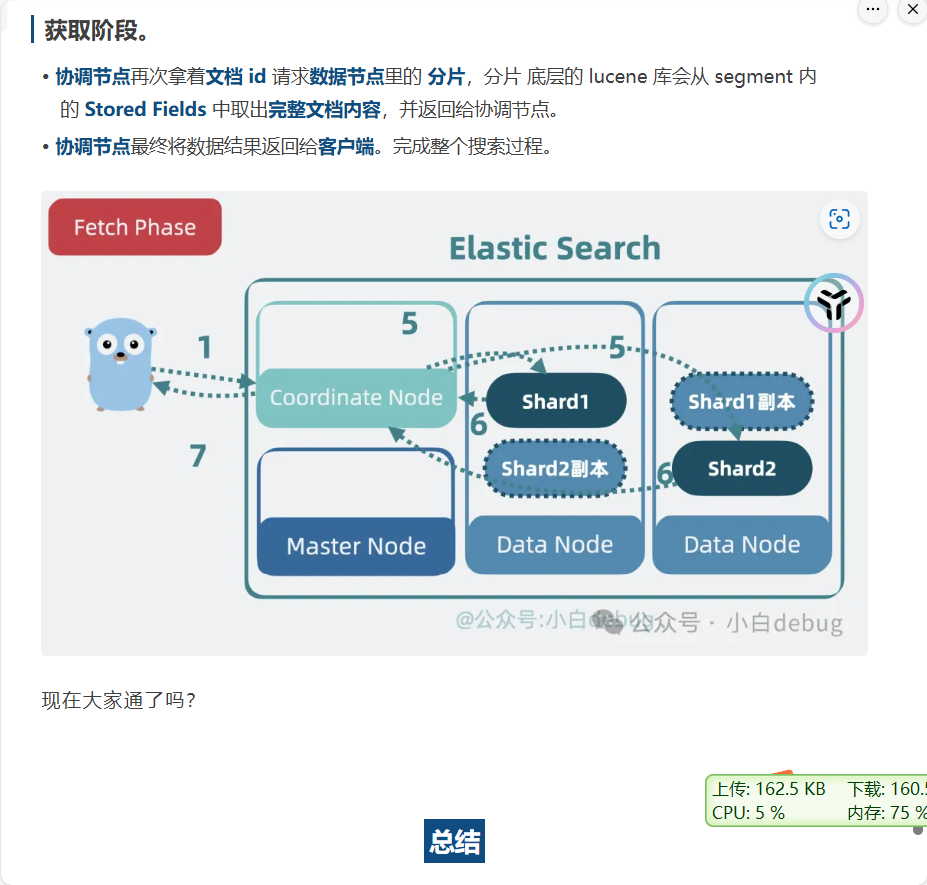
查询阶段
和之前写入阶段,差不多,但是是并发查询segment,然后协调节点来进行排序聚合。
之后根据doc id再次获取完整的内容

All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.

