
mysql学习
MySQL是怎样运行的
0.语法篇
常用的关键字:
- distinct,select distinct* from来进行去重
- 排序order by id des(下降
- in(a,b)==a or b
- 查询的时候,列可以直接进行操作,如果我们要求对(欸一个分数+10)==select score+10 from
- null无论什么操作还是null
- 字符串函数啊,left,right,substr都是进行截取
- count(列名)就是来进行统计由多少个
- 分组查询,这个相当于多个目录(省,市,县来进行分段)使用group by province
- 例如求语文,英语,数学的平均分,写三个函数太累,select avg(subject) from group by subject
- 分组之后先接着进行过滤,例如,只想统计分数平均值大于60,后面市having by(不能用where,因为这是计算后的结果)
- 多表查询,外连接,分为做连接,还有右连接(核心就是完整的保留那一边),内连接就是只有都相等才进行保留
- 子查询,select * where id=(查询语句),根据查询语句返回的结果再次进行查询
- 并集查询,使用union查询多个,会过滤重复的结果
- 视图view,相当于自己预先定义函数,然后进行了查询的结果存放的地方,再视图里操作页会影响原始表
- 储存程序,相当于函数,可以设定变量,@a来进行对变量a来进行赋值,会有返回值
- 储存过程,没有返回值,直接进行操作
- 下一个就是游标,相当于list
- trigger触发器,就是进行检查,可以自定义每次增加删除,检查分数是不是小于100
1.前言篇
执行一条sql,都发生了什么
主要包含一下流程,首先是连接启,之后查询缓存,缓存失败,进行语法分析,解析阿来就是对语法进行优化,然后才是执行,之后返回结果
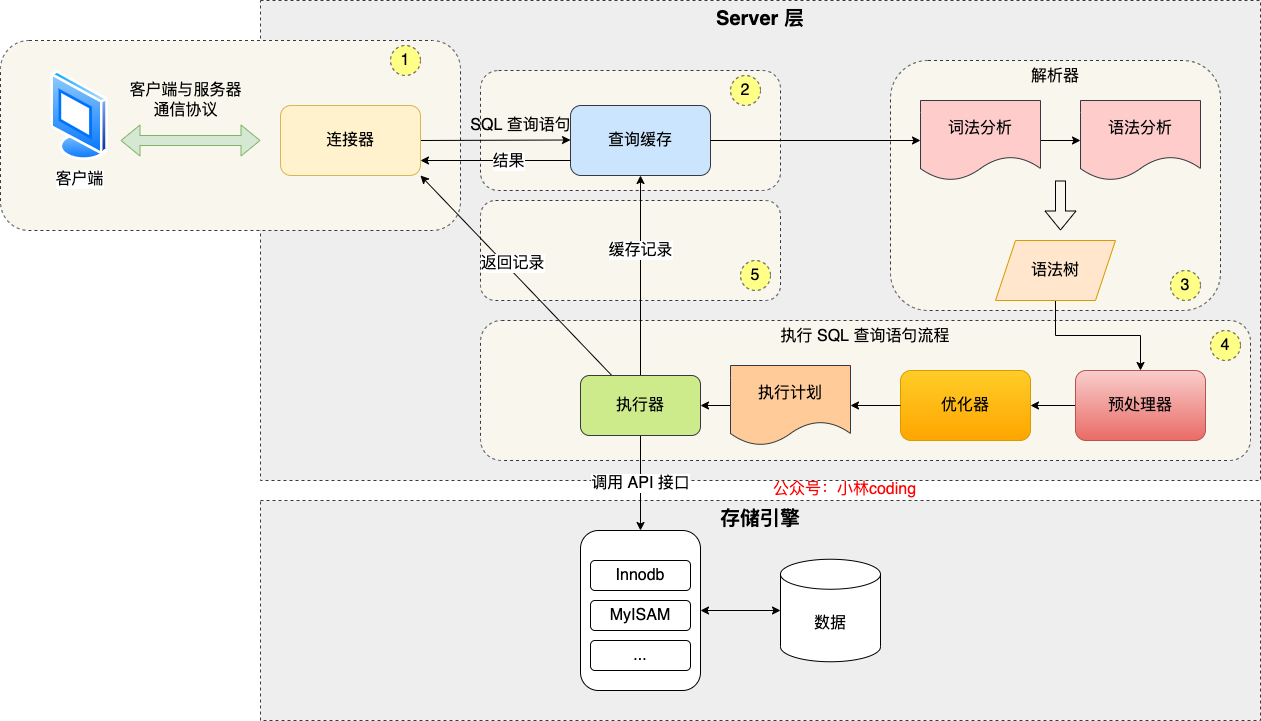
- server负责api的调用,分析还有执行sql,常用的存储过程还有触发器,视图都在这一层
- 存储层负责的是数据的存放还读取,数据库的innodb索引都在这一层
1.连接器
负责身份认证还有权限相关的(登录mysql的时候)
show processlist查看当前的连接数目,空闲时间超过wait_time会哦被断开,最大的连接再max_connection上面,
2.查询缓存
mysql8.0删除这个功能了因为对于更新比较频繁的表,这个缓存基本就没有用,更新一次就删除缓存一次.
3.分析器
作用就是对语句进行分析,看这条语句要干什么.主要包括语法分析还有此法分析,语法分析就是看你是不是输入错误的单词,此法分析就是提取关键词
4.执行器
执行sql查询语句,首先第一步就是看你有没有权限来查这个
- 预处理器,检查是不是含有这个字段,把*替换成全表
- 优化器主要确定查询方案,因为一个数据库可能有多条索引,查找时间最小的
- 执行器执行,主键索引查询,全表查询,索引下推(建立二级索引agename,这个索引,直接根据开闭原则来进行判断)
2.mysql的一行记录是怎么存放的
可以看到,共有三个文件,这三个文件分别代表着:
- db.opt,用来存储当前数据库的默认字符集和字符校验规则。
- t_order.frm ,t_order 的表结构会保存在这个文件。在 MySQL 中建立一张表都会生成一个.frm 文件,该文件是用来保存每个表的元数据信息的,主要包含表结构定义。
- t_order.ibd,t_order 的表数据会保存在这个文件。表数据既可以存在共享表空间文件(文件名:ibdata1)里,也可以存放在独占表空间文件(文件名:表名字.ibd)。这个行为是由参数 innodb_file_per_table 控制的,若设置了参数 innodb_file_per_table 为 1,则会将存储的数据、索引等信息单独存储在一个独占表空间,从 MySQL 5.6.6 版本开始,它的默认值就是 1 了,因此从这个版本之后, MySQL 中每一张表的数据都存放在一个独立的 .ibd 文件。
好了,现在我们知道了一张数据库表的数据是保存在「 表名字.ibd 」的文件里的,这个文件也称为独占表空间文件
一张表的结构再frm里面,数据再ibd里面
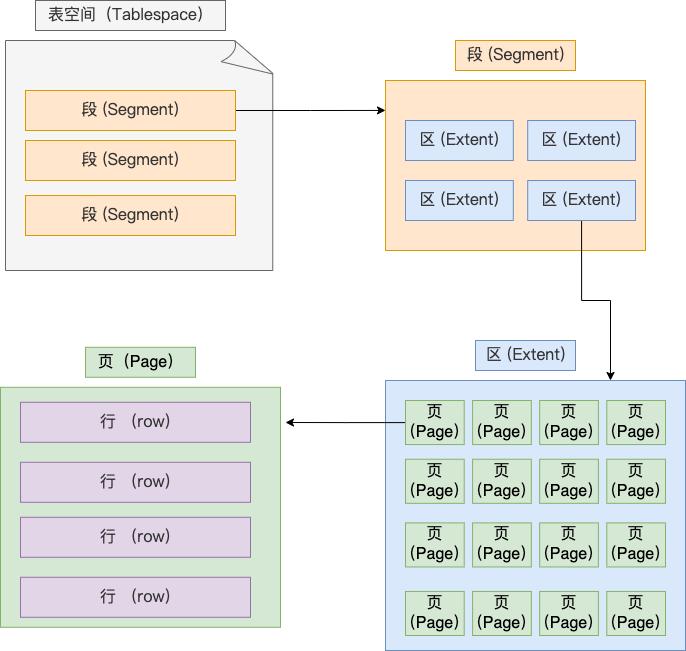
一个表空间可以由多个段组成,段是可以由多个不连续的区构成,区是由连续的页构成,页是由连续的记录进行组成
页:
一个页大小是16kb,mysql的读写都是以页为单位,长江的页还有数据页面,undo页面,还有redo
区:
一个区的大小是1MB,那么就有64个页面,为了让相邻的两个页面的物理位置相邻,划分的一个1MB物理空间,这样就是顺序io
在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区(extent)为单位分配。每个区的大小为 1MB,对于 16KB 的页来说,连续的 64 个页会被划为一个区,这样就使得链表中相邻的页的物理位置也相邻,就能使用顺序 I/O 了。
段:
段是由多个区间构成的,一般分为索引段
- 索引段:存放 B + 树的非叶子节点的区的集合;
- 数据段:存放 B + 树的叶子节点的区的集合;
- 回滚段:存放的是回滚数据的区的集合,之前讲事务隔离 (opens new window)的时候就介绍到了 MVCC 利用了回滚段实现了多版本查询数据。
索引都在非叶子节点上面,数据都在叶子上面,还有回滚数据
3.索引
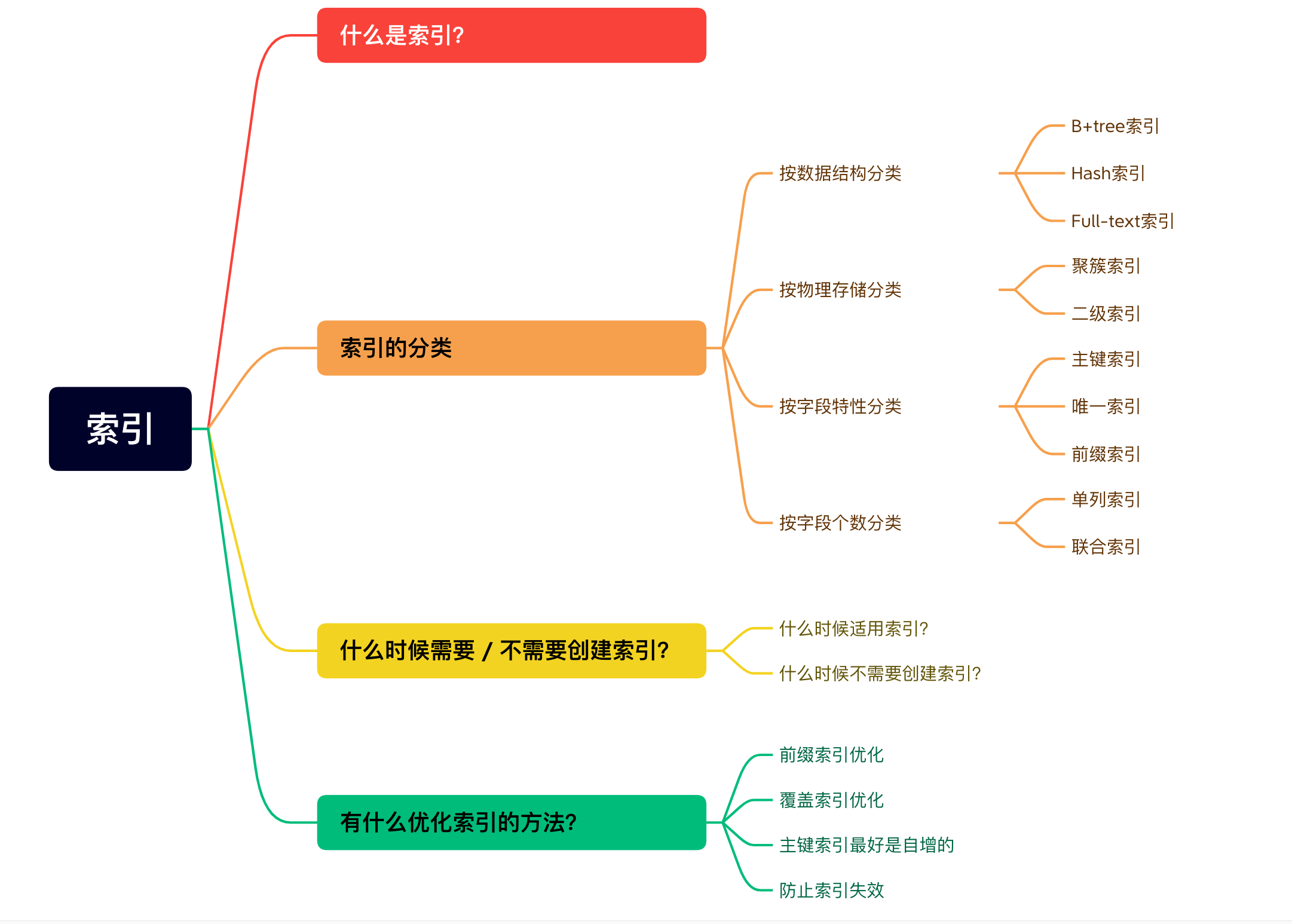
3.1索引简介
索引是一种排好序的数据结构,作用相当于数据的目录
优缺点:
- 减少查询时间
- 但是数据增删改的时候会更新索引
- 会浪费一定的物理空间
3.2索引的分类
数据结构;b+,hash,full-text
物理结构:主键索引,耳机索引(两个关键字何在一起)
字段:主键,唯一(unique),普通,前
数据结构:
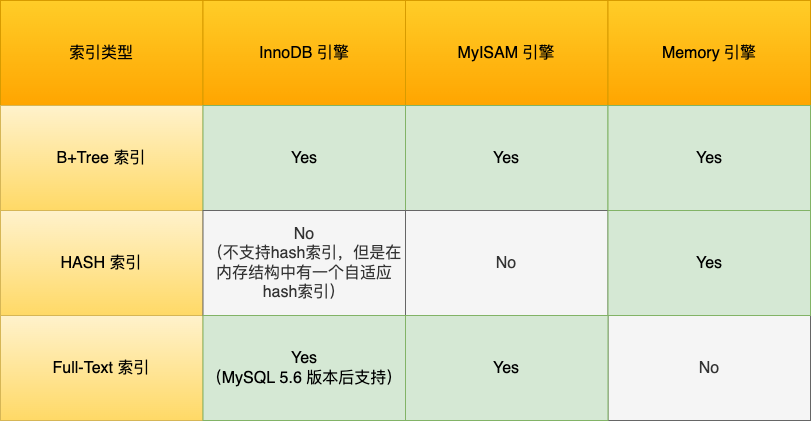
主键查询,
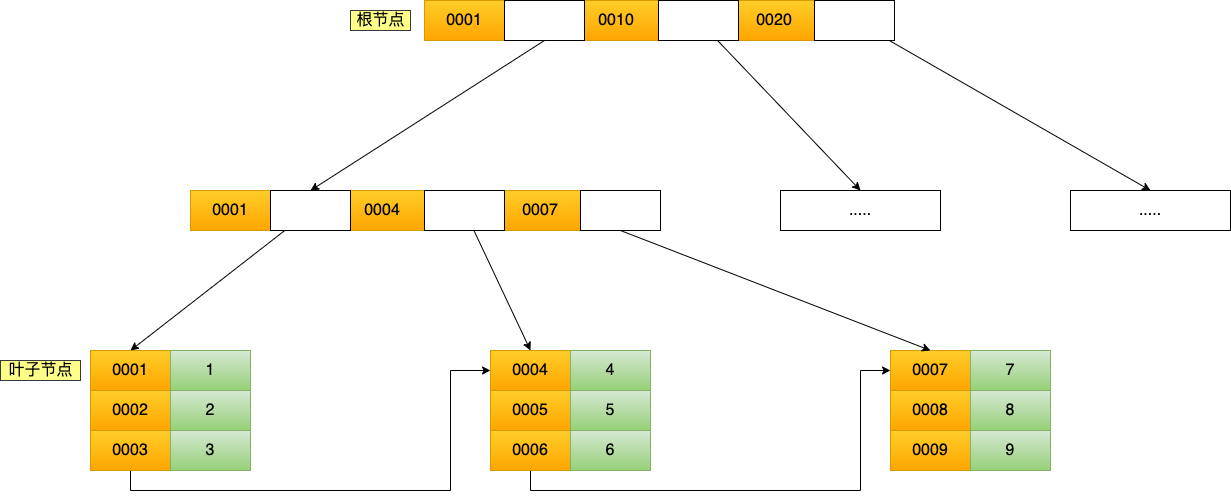
最后一层才是数据节点,主键索引的是全部数据,耳机索引知识主键值,然后进行徽标才能得到值
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
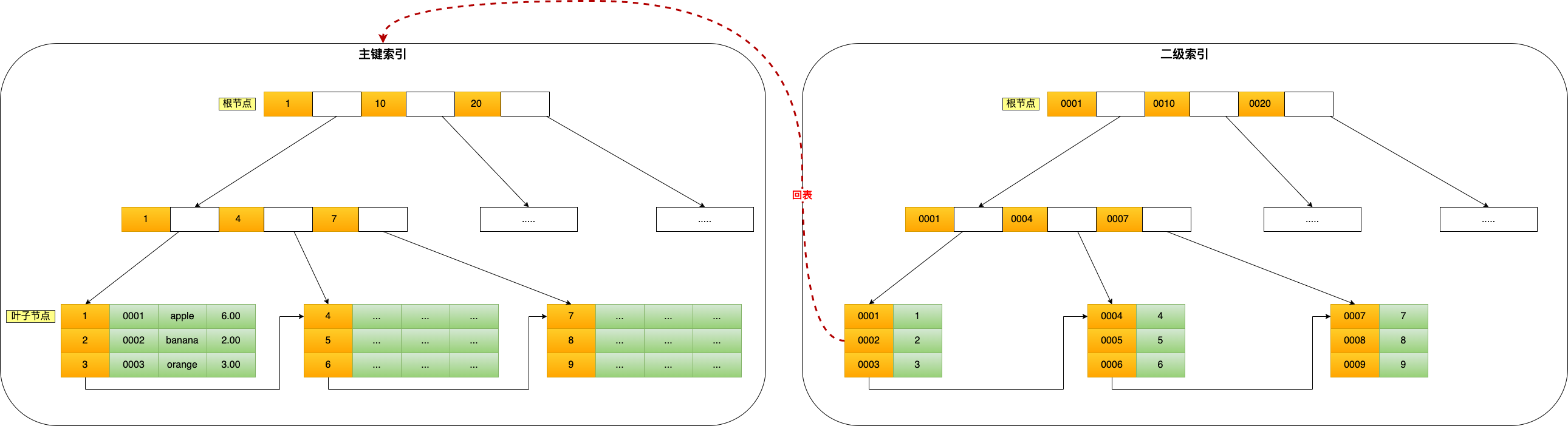
3.3B树与B+树
- B树每个节点都有数据,b+树只有页节点才有数据
- b树的叶节点是单独存在的,但是b+树是用单链表连接到下一个的
因为 B+ 树所有叶子节点间还有一个链表进行连接,这种设计对范围查找非常有帮助,比如说我们想知道 12 月 1 日和 12 月 12 日之间的订单,这个时候可以先查找到 12 月 1 日所在的叶子节点,然后利用链表向右遍历,直到找到 12 月12 日的节点,这样就不需要从根节点查询了,进一步节省查询需要的时间
索引下推:
- 在 MySQL 5.6 之前,只能从 ID2 (主键值)开始一个个回表,到「主键索引」上找出数据行,再对比 b 字段值。
- 而 MySQL 5.6 引入的索引下推优化(index condition pushdown), 可以在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
就是说,可以直接用联合索引来进行提权哦判断不符合的数据
3.4什么时候需要索引
- id唯一
- 经常使用where,order by,groupby的字段
不用的情况:不用where的字段,大量重复数据sex
4.InnoDB引擎
这一章主要是讲MySQL默认引擎,包括基本单位,还有管理的基本单位
4.1简介
- 盘与内存使用的是页,一个页大小是16kB
- innoDB存放每一条记录叫做行
- 行是由头信息还有数据信息组成
- 主要有下面四种格式,compact,redunnat
- 首先是compact,(前面得到头信息,记录可变唱的字段,然后从小到大来记录,每一个字段的长度)
- 第二个就是记录这一行的null的数量(记录方法是one-hot方法,每一个列都是01表示)
插入代码块如下
1 | alterr table student row_format = compact |

记录的真实数据,包含三个隐藏列,默认idrow,trx表示食物id,是哪一个事务生成的,roll point代表回滚的
varchar(n) 中 n 最大取值为多少?
一行记录最大能存储 65535 字节的数据,但是这个是包含「变长字段字节数列表所占用的字节数」和「NULL值列表所占用的字节数」。所以, 我们在算 varchar(n) 中 n 最大值时,需要减去这两个列表所占用的字节数。
如果一张表只有一个 varchar(n) 字段,且允许为 NULL,字符集为 ascii。varchar(n) 中 n 最大取值为 65532。
计算公式:65535 - 变长字段字节数列表所占用的字节数 - NULL值列表所占用的字节数 = 65535 - 2 - 1 = 65532。
如果有多个字段的话,要保证所有字段的长度 + 变长字段字节数列表所占用的字节数 + NULL值列表所占用的字节数 <= 65535。
MySQL 中磁盘和内存交互的基本单位是页,一个页的大小一般是
16KB,也就是16384字节,而一个 varchar(n) 类型的列最多可以存储65532字节,一些大对象如 TEXT、BLOB 可能存储更多的数据,这时一个页可能就存不了一条记录。这个时候就会发生行溢出,多的数据就会存到另外的「溢出页」中。
4.2INnoDB数据页结构

这一张主要讲解的是数据页,还有B+树的实现,介绍数据页的结构,包括记录,还有头结构
- 每一条记录都是存放在user record
- n_owned 记录拥有的小弟
- next记录吓一跳页面
- 还有两条虚拟记录,一个是infir+super
- free space是记录空闲空间
- page dir表示这是不是叶子节点
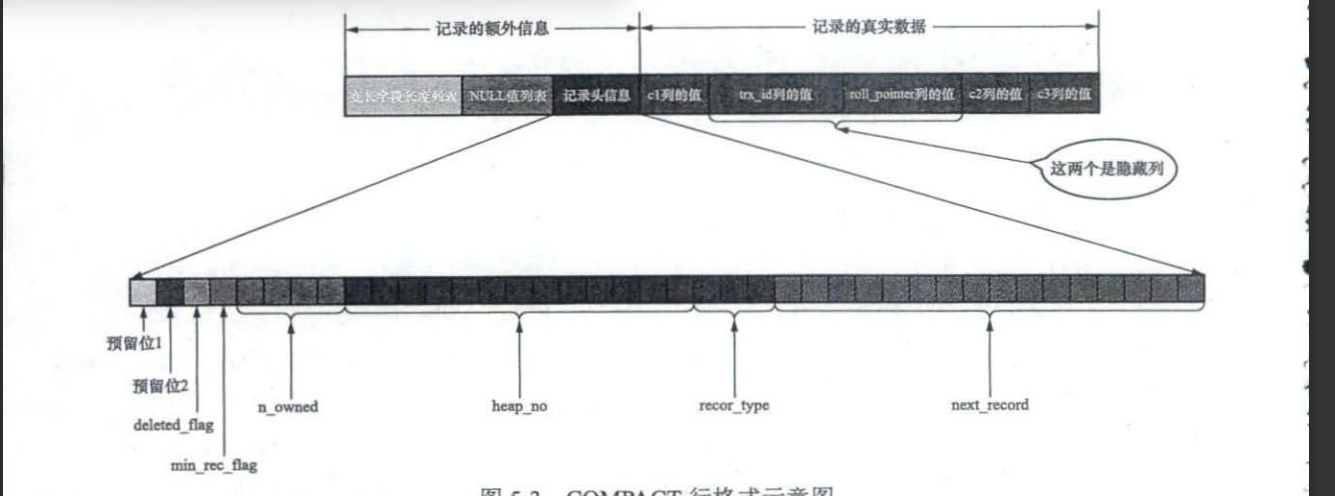 ****
****
这是一条记录头信息,有包括id,还有拥有的小弟
头信息:del——flag,next record吓一跳记录,heap_no相对记录在堆,还有一个type,表示是
删除记录:并不是在页面实际删除,而是设置一个del标记为1
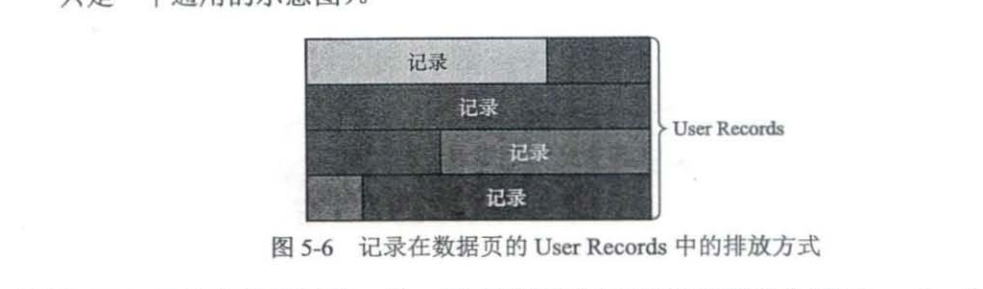
主每一条记录都用于n——cow这个适用于分组的,然后del代表为是不删除,还有相对位置,之后就是下一个记录的位置
然后有两条虚拟记录,一个是最小的,还有一个是最大记录,当相当于虚拟头结点还有虚拟尾结点
这两个位置是最靠前的一个是0,一个是1,
page dire:这个作用就是为了把之前的记录进行3-4个一组来进行结合,记录最后一个索引最大的值为slot,n_row代表的是还有几个小弟
每一个slot代表
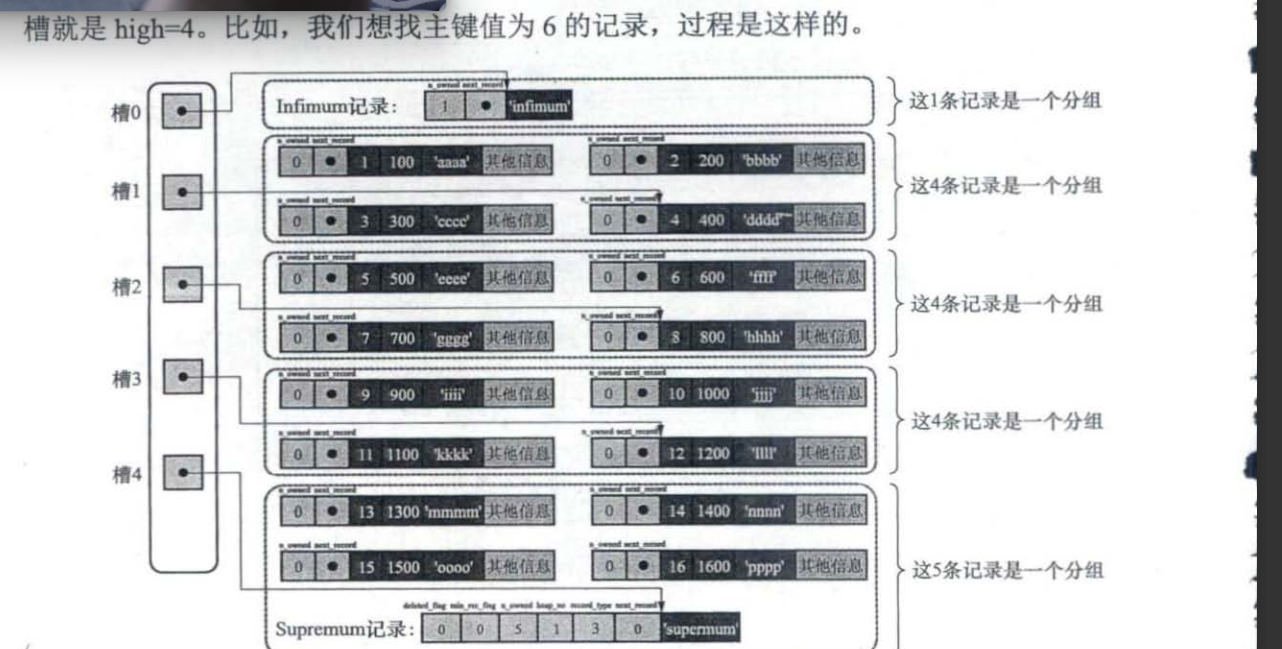
每一个slot代表一个地址

- 一个页面是包含多个记录的
- 一个页面要进行分组,最小记录还有最大记录,之后就是数据记录来进行分组
- 分组最大的放入slot里面,他记录自己包含的小弟
从图可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照「主键值」从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。
B+树每一个节点都是数据页
- 只有叶子节点(最底层的节点)才存放了数据,非叶子节点(其他上层节)仅用来存放目录项作为索引。
- 非叶子节点分为不同层次,通过分层来降低每一层的搜索量;
- 所有节点按照索引键大小排序,构成一个双向链表,便于范围查询;
5.事务
事务是逻辑上一组操作,要么执行,要么不执行.实现事务,要遵循4个特性,aicd(原子性,一致性,隔离性,最后就是持久性)一只猩猩,就是操作完成,还是满足约束,隔离性,不会对其他事务进行影响.
5.1并发事务带来的影响
会出现,脏读,不可重复,幻读.
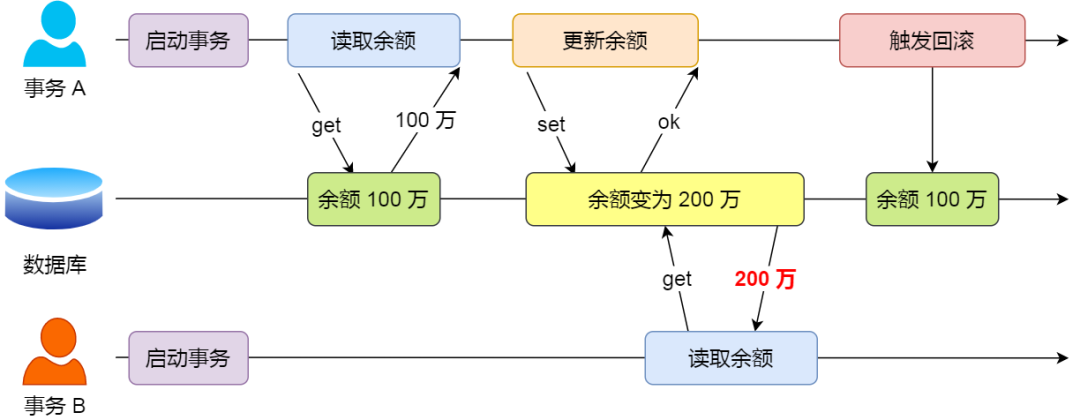
脏读:读取没有提交的值,然后值又进行回滚了
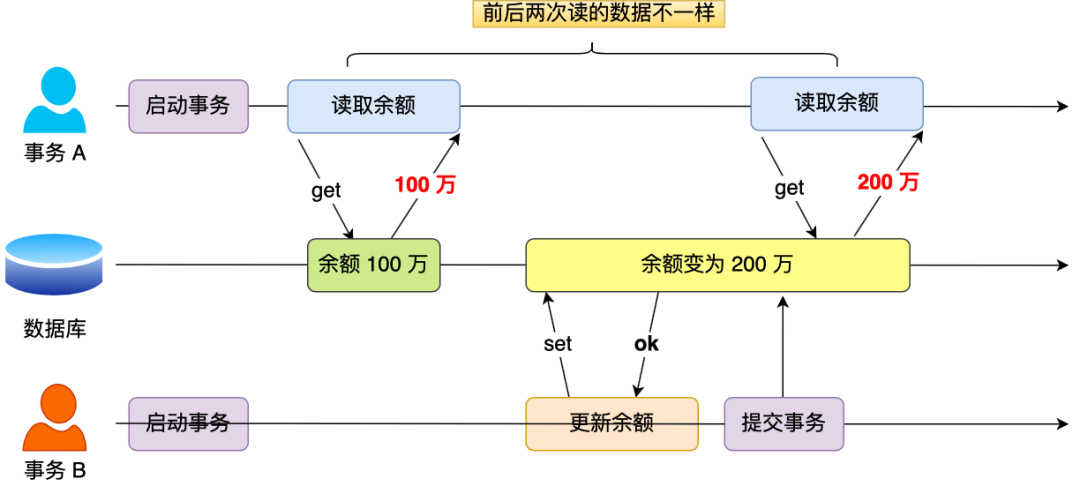
不可重复读:
读取的值被修改,两次读取不一样
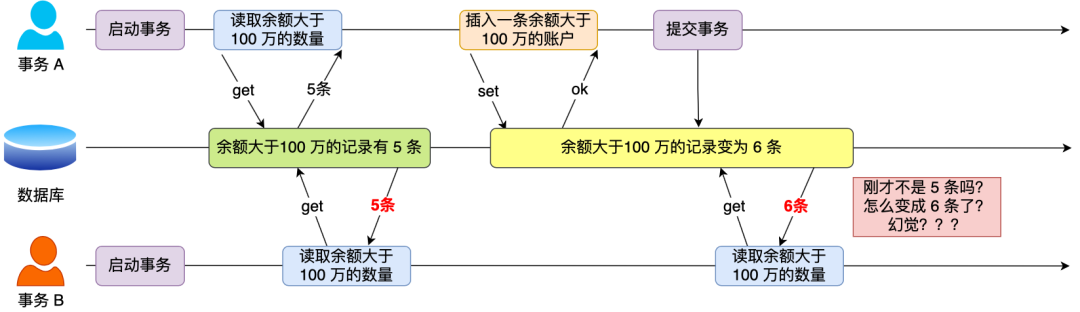
幻读:
读取了值,结果下一次读取的时候被删除了
四种隔离级别:
- 未提交读(脏读,幻读,可重复)
- 提交读(幻读,可重复)
- 可重复读(幻读)
- 可串行化
可重复读很大程度避免了幻读
并发事务 的控制方法:基于锁还有mvcc(多版本并发控制)乐观
mvcc:hi一份数据多个版本,可以通过事务id,查找之前的版本
MySQL 的隔离级别是基于锁实现的吗?
MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
对于四种隔离事务的实现方法
- 读未提交:直接读取最新的就行
- 可串行化通过枷锁来进行读取
- 读提交,使用read view来进行创建快照,读取事务处理王的结果.可重复读是只读取,生成时候的视图值
mvcc版本控制的实现
在内部,
InnoDB存储引擎为每行数据添加了三个 隐藏字段open in new window:
DB_TRX_ID(6字节):表示最后一次插入或更新该行的事务 id。此外,delete操作在内部被视为更新,只不过会在记录头Record header中的deleted_flag字段将其标记为已删除DB_ROLL_PTR(7字节)回滚指针,指向该行的undo log。如果该行未被更新,则为空DB_ROW_ID(6字节):如果没有设置主键且该表没有唯一非空索引时,InnoDB会使用该 id 来生成聚簇索引
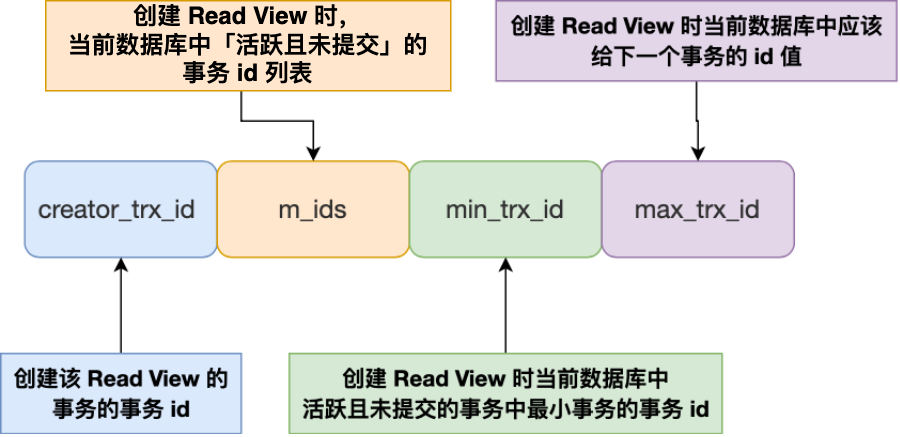
- create:创建的时候的id
- m_id,当前的事务id列表(启动了,但是没有提交的事务)
- min是最小的事务id
- max是下一次事务的id
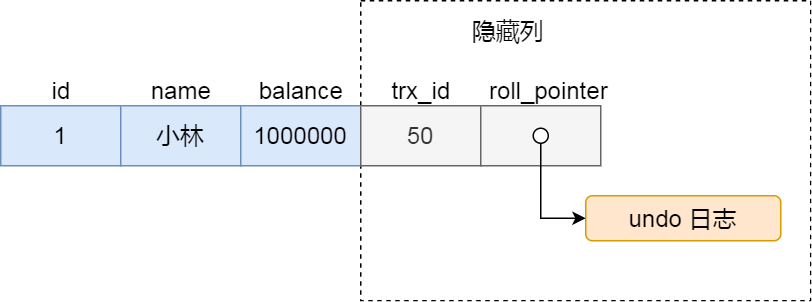
每次进行事务操作的时候,会把trx_id更新为当前id,然后roll_point只想前一个版本,同时把前一个版本写入到undo文件里面
undo文件:用来回滚的,还有一个作用就是mvcc
- 小于min的事务都可见
- 大于max的都不可见
- 处于min与max之间的,需要判断是不是再ids列表里面,不在就是可见
可重复读是如何实现的
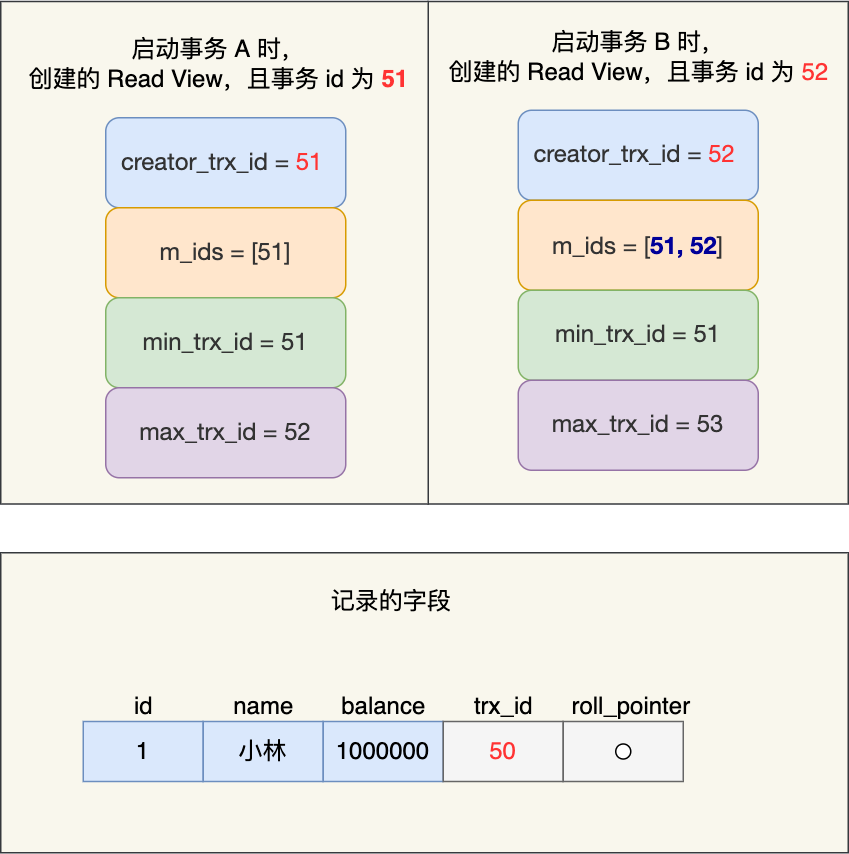
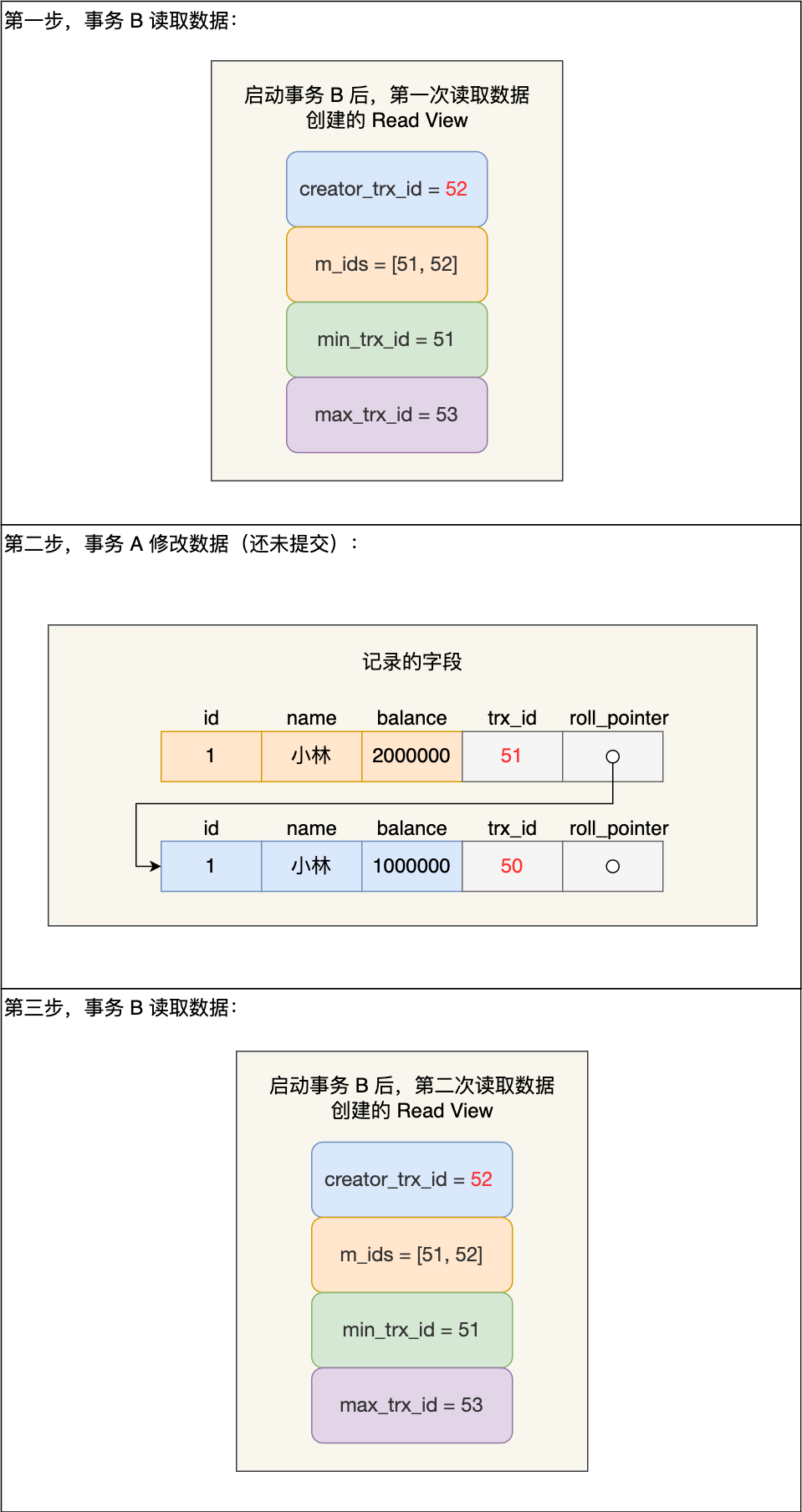
开始的时候createid是自己,列表也是只有自己,所以a是可以一直
B 第一次读小林的账户余额记录,在找到记录后,它会先看这条记录的 trx_id,此时发现 trx_id 为 50,比事务 B 的 Read View 中的 min_trx_id 值(51)还小,这意味着修改这条记录的事务早就在事务 B 启动前提交过了,所以该版本的记录对事务 B 可见的,也就是事务 B 可以获取到这条记录。
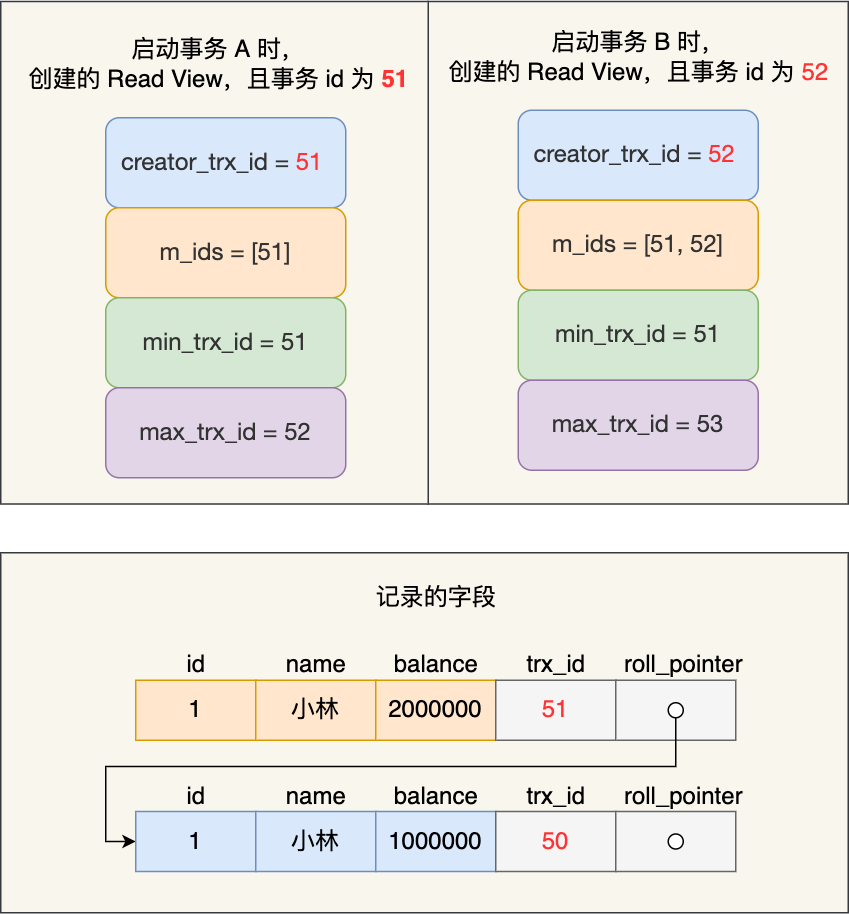
接着,事务 A 通过 update 语句将这条记录修改了(还未提交事务),将小林的余额改成 200 万,这时 MySQL 会记录相应的 undo log,并以链表的方式串联起来,形成版本链,如下图:

你可以在上图的「记录的字段」看到,由于事务 A 修改了该记录,以前的记录就变成旧版本记录了,于是最新记录和旧版本记录通过链表的方式串起来,而且最新记录的 trx_id 是事务 A 的事务 id(trx_id = 51)。
然后事务 B 第二次去读取该记录,发现这条记录的 trx_id 值为 51,在事务 B 的 Read View 的 min_trx_id 和 max_trx_id 之间,则需要判断 trx_id 值是否在 m_ids 范围内,判断的结果是在的,那么说明这条记录是被还未提交的事务修改的,这时事务 B 并不会读取这个版本的记录。而是沿着 undo log 链条往下找旧版本的记录,直到找到 trx_id 「小于」事务 B 的 Read View 中的 min_trx_id 值的第一条记录,所以事务 B 能读取到的是 trx_id 为 50 的记录,也就是小林余额是 100 万的这条记录。
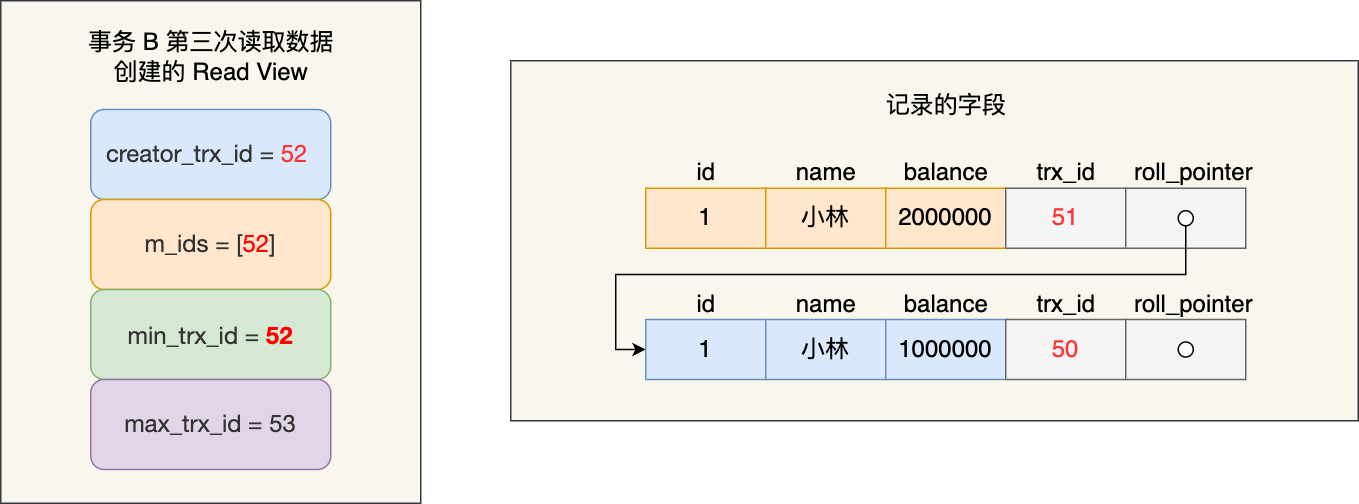
最后,当事物 A 提交事务后,由于隔离级别时「可重复读」,所以事务 B 再次读取记录时,还是基于启动事务时创建的 Read View 来判断当前版本的记录是否可见。所以,即使事物 A 将小林余额修改为 200 万并提交了事务, 事务 B 第三次读取记录时,读到的记录都是小林余额是 100 万的这条记录。
就是说:对于事务a已经完成了,他的记录里面的trx更新为51,但是51再事务b里面,所以他要往前寻找第一个小于事务b的min的trx,然后就是50,因此取出50来作为记录
读提交是怎么实现的
读提交隔离级别是在每次读取数据时,都会生成一个新的 Read View。
而对于幻读现象,不建议将隔离级别升级为串行化,因为这会导致数据库并发时性能很差。MySQL InnoDB 引擎的默认隔离级别虽然是「可重复读」,但是它很大程度上避免幻读现象(并不是完全解决了,详见这篇文章 (opens new window)),解决的方案有两种:
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select … for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select … for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。
对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同:
- 「读提交」隔离级别是在每个 select 都会生成一个新的 Read View,也意味着,事务期间的多次读取同一条数据,前后两次读的数据可能会出现不一致,因为可能这期间另外一个事务修改了该记录,并提交了事务。
- 「可重复读」隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View,这样就保证了在事务期间读到的数据都是事务启动前的记录。
这两个隔离级别实现是通过「事务的 Read View 里的字段」和「记录中的两个隐藏列」的比对,来控制并发事务访问同一个记录时的行为,这就叫 MVCC(多版本并发控制)。
在可重复读隔离级别中,普通的 select 语句就是基于 MVCC 实现的快照读,也就是不会加锁的。而 select .. for update 语句就不是快照读了,而是当前读了,也就是每次读都是拿到最新版本的数据,但是它会对读到的记录加上 next-key lock 锁。

