
mitos
6.S081
这是mit的公开课,使用xv6来自己实现一个小的操作系统。
0.预备环节
0.1安装linux
本人直接使用的是wsl,安装的是debian系统,可以参照官网的实验步骤。唯一的坑点就是git残酷使用的ssh,不知道是梯子问题,还是校园网问题,一直git不了,课允许lan,一直没有反应,最后还是直接在windows下使用git http才弄下来。
0.2安装vscode
vscode主要是讲解如何来配置wsl。需要安装2个插件,一个wsl还有一个是c语言插件。然后重点就是下面三个文件的配置,一个task,一个launch,还有一个是c++——properties,参考下面的连接
Visual Studio Code 中的 Linux C++ 和 Windows 子系统入门
- tasks。json(配置编译器的位置,还有编译时候所需要的参数-o,-g
- 这个是调试选项launch,这个是放入gdb的,有工作目录,还有调试的程序
- 最后一个properties就是配置gcc还有gdb的位置
开始扩展:
参考这个视频
mit6s081 通过vscode来debug kernel_哔哩哔哩_bilibili
一直以来的vscode的配置都是直接抄的别人配置好的,对vscode 的task.json haiyou launch.json都有一种莫名的不要输系感觉.并且对使用用gdb来进行调试c制作的make程序都深恶痛绝.直到今天,看完这个视频,才发现并没有多么的可怕.
下面将要来介绍一下launch.json的配置是为什么
- 首先launch.json这个是用来调试的
- 调试那么就需要调试器吧,调试器就是gdb
- i那位这个riscv,一般的gdb是只能x64,所以需要使用gdb-mul
- 然后调试的话,你也需要调试的文件吧,文件就是kernel/kernel,因为xv6最开始是从kernel启动的
- miDebuggerServerAddress这个是远程调试的后端,就是输入make qemu-gdb产生的地址
- 然后按住F5就可以启动
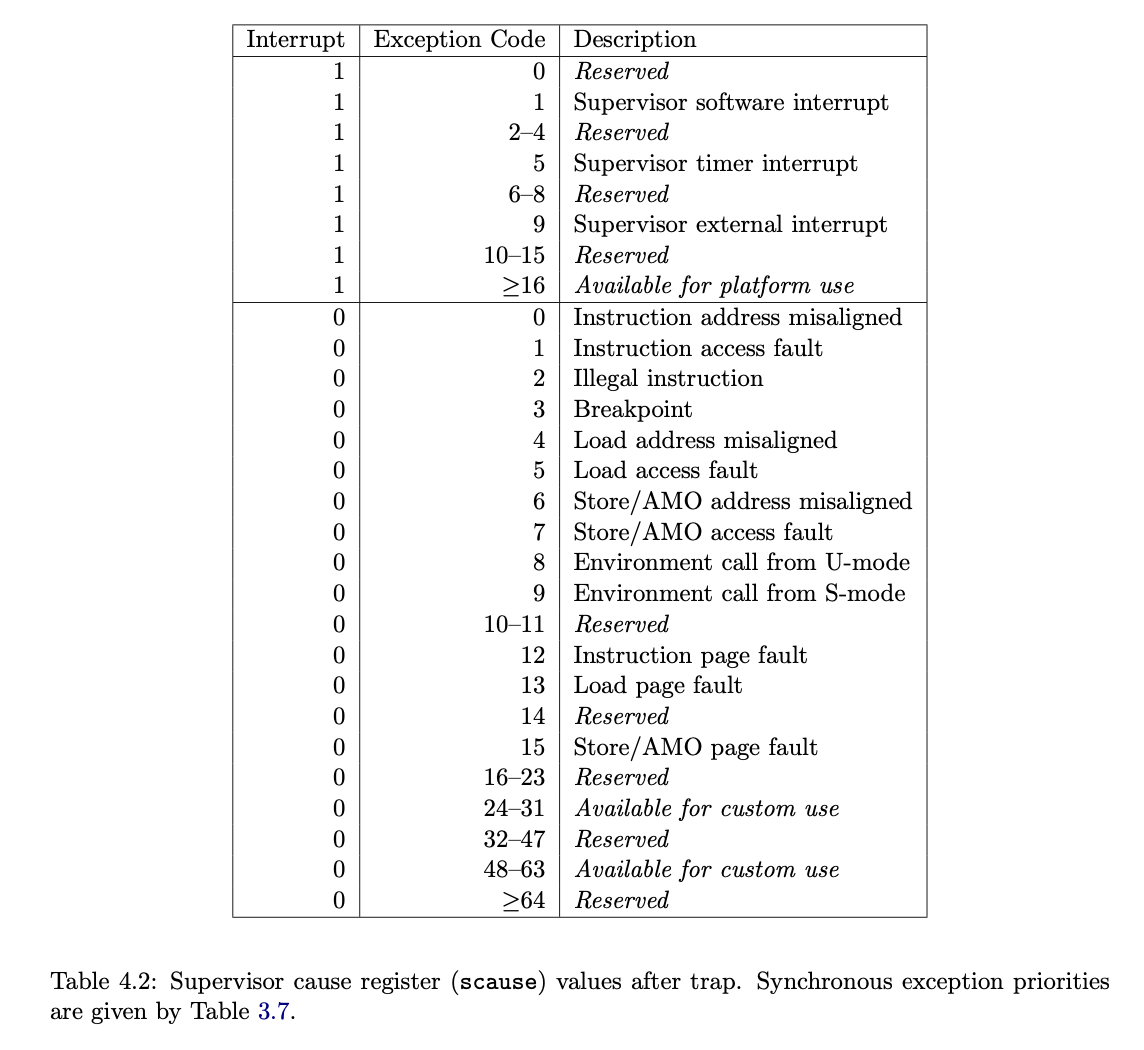
1 |
|
问题来了,每次我要进行调试,都要自己手动输入一次make qemu-gdb,那么这就相当于一次任务,我们可以值在执行调试的时候,先执行这个,那么可以顶一个pretask,task.json的任务就是制作一个任务,同理,我们如果按照之前,手工运行的话,可以直接制作一个task,就可以直接运行了
1 | // launch.json |
常规的c定义
1 | { |
1.lab util
Lab: Xv6 and Unix utilities (mit.edu)
Lec01 Introduction and Examples (Robert) - MIT6.S081 (gitbook.io)
第一章 操作系统接口 · 6.S081 All-In-One (dgs.zone)
MIT 6.S081 Lab Util 实验 | Ray’s Blog (rayzhang.top)
本次实验主要参考以上四个网站,视频没有看,直接看的博主翻译的文稿,感觉翻译的文稿比视频好很多.
考研的时候学过操作系统了的,就没怎么看视频,直接找的几个重点章节看了一下.现在复习一下基础知识.
第一章 操作系统接口 · 6.S081 All-In-One (dgs.zone)
直接看这本书就行,主要第一张江的是进程相关的内容,应该算进程管理吧.
1.1进程和内存
用户态通过调用内核态的fork接口来进行创建内存,对于子进程来讲,自己的pid是0,但是对于父进程来讲,自己的pid是大于0的,因此,我们考研来进行判断
1 | // fork()在父进程中返回子进程的PID |
这个是会反应两个结果的,一个是父进程输出parent,通过调用fork达到子进程,此时自己的pid是0,所以输出child
1 | parent: child=1234 |
同时我们可以使用exec来执行相关shell命令,直接在用户太执行.
1 | char* argv[3]; |
1.2 I/O和文件描述符
主要讲的是io的读取和写入的api使用,使用write还有read.
1 | n = read(0, buf, sizeof buf); |
0代表标准输入流,就是我们输入的东西,buf就是要接受储存的字符串,最后一个是长度,我要接受多长的字符串.
同理,write就是写入,这个是写入到标准输出流.第一个是要写的保存的地方,然后就是要写的字符串,还有长度.
1 | write(1, "hello ", 6); |
1.3 管道
管道就是用于进程通信的,一个用来读取,一个写入 .只能单向联通,半双工.写入的时候读取必须关闭.
使用方法就是创建一个二位数组,通过pipe来进行调用创建管道,使用close来关闭管道一端然后调用上次的read还有write方法来进行读取还有写入.
1 | int p[2]; |
程序调用pipe,创建一个新的管道,并在数组p中记录读写文件描述符。在fork之后,父子进程都有指向管道的文件描述符。子进程调用close和dup使文件描述符0指向管道的读取端(前面说过优先分配最小的未使用的描述符),然后关闭p中所存的文件描述符,并调用exec运行wc。当wc从它的标准输入读取时,就是从管道读取。父进程关闭管道的读取端,写入管道,然后关闭写入端。
接起来。然后对管道的左端调用
fork和runcmd,对管道的右端调用fork和runcmd,并等待两者都完成。管道的右端可能是一个命令,该命令本身包含一个管道(例如,a | b | c),该管道本身fork为两个新的子进程(一个用于b,一个用于c)。因此,shell可以创建一个进程树。这个树的叶子是命令,内部节点是等待左右两个子进程完成的进程。
队友左右节点都是自己进行创建一个新的fork然后执行之后来返回
1.4 文件系统
文件系统就是文件分为文件还有文件夹,文件夹是一个特殊的数据结构,里面包含当前文件夹的所有名称还有他的大小.
通过调用这个方法来得到答案
这个stat是类型,如果是文件夹还有一个数据结构
1 |
|
1.5实验
1.5.1boot
启动过程,首先就是git’数据,直接登录网页使用github来进行下载,使用ssh一直卡死.之后切换分支到util就行,然后执行 make qemu.毕竟这个实验是在qemu上进行模拟的
1.5.2sleep (easy)
实现sleep函数.我们可以根据下面提示来进行做
- Before you start coding, read Chapter 1 of the xv6 book.
- Look at some of the other programs in
user/(e.g.,user/echo.c,user/grep.c, anduser/rm.c) to see how you can obtain the command-line arguments passed to a program.- If the user forgets to pass an argument, sleep should print an error message.
- The command-line argument is passed as a string; you can convert it to an integer using
atoi(see user/ulib.c).- Use the system call
sleep.- See
kernel/sysproc.cfor the xv6 kernel code that implements thesleepsystem call (look forsys_sleep),user/user.hfor the C definition ofsleepcallable from a user program, anduser/usys.Sfor the assembler code that jumps from user code into the kernel forsleep.- Make sure
maincallsexit()in order to exit your program.- Add your
sleepprogram toUPROGSin Makefile; once you’ve done that,make qemuwill compile your program and you’ll be able to run it from the xv6 shell.- Look at Kernighan and Ritchie’s book The C programming language (second edition) (K&R) to learn about C.
看ls是如何获取到参数的,如果没有参数,直接反悔哦失败,传递的参数是字符串,你需要使用atoi,直接使用系统调用的sleep功能.然后调用exit来推出这个程序.最后把这个给功能加入到makefile里面.
上面已经给出了了具体思路,我们只需要写代码就行.
1 |
|
argc是参数个数,argv是参数字符串列表,如果c<2就是不合法,然后直接进行执行调用系统api.之后就是加入到makefile里面.
1.5.3pingpong (easy)
实现pingpong功能就是,具体要求就是两个管道,一个父亲写,儿子读取,一个儿子读取谷歌的父亲管道,然后写入到自己的管道,父亲来读取.使用wait可以保真先后顺序.
Write a program that uses UNIX system calls to ‘’ping-pong’’ a byte between two processes over a pair of pipes, one for each direction. The parent should send a byte to the child; the child should print “
: received ping”, where is its process ID, write the byte on the pipe to the parent, and exit; the parent should read the byte from the child, print “ : received pong”, and exit. Your solution should be in the file user/pingpong.c.
- Use
pipeto create a pipe.- Use
forkto create a child.- Use
readto read from the pipe, andwriteto write to the pipe.- Use
getpidto find the process ID of the calling process.- Add the program to
UPROGSin Makefile.- User programs on xv6 have a limited set of library functions available to them. You can see the list in
user/user.h; the source (other than for system calls) is inuser/ulib.c,user/printf.c, anduser/umalloc.c.
根据上面提示,使用pipe创建两个管道,然后使用fork创建孩子进程,之后是以哦那个read来读取,和write来写入.注意要进行关闭管道的一端.只允许单项流通.
1 |
|
首先if的是孩子进程,所以我们关闭父亲写入的,来进行读取,同时关闭孩子的读取来进行写入,把读取的写入到矮子里面.之后就是父亲,父亲是自己先进行写入,然后读取孩子的,也要进行关闭程序.
1.5.4primes (moderate)/(hard)
write a concurrent version of prime sieve using pipes. This idea is due to Doug McIlroy, inventor of Unix pipes. The picture halfway down this page and the surrounding text explain how to do it. Your solution should be in the file
user/primes.c.
题目要求,并发使用管道来进行读取输出2-35的素数.思路是一个写入2-35的管道,另外一个管道来进行输出.
- Be careful to close file descriptors that a process doesn’t need, because otherwise your program will run xv6 out of resources before the first process reaches 35.
- Once the first process reaches 35, it should wait until the entire pipeline terminates, including all children, grandchildren, &c. Thus the main primes process should only exit after all the output has been printed, and after all the other primes processes have exited.
- Hint:
readreturns zero when the write-side of a pipe is closed.- It’s simplest to directly write 32-bit (4-byte)
ints to the pipes, rather than using formatted ASCII I/O.- You should create the processes in the pipeline only as they are needed.
- Add the program to
UPROGSin Makefile.
这个提示没什么用,直接看的大佬的版本,思路就是使用快速筛,蠡口上有讲解.主要思路就是第一遍把2的倍数全被设置true,剩下的从false里面读取,如果是当前的倍数的,也设置成true,指导到最后一个值.(这个给可以使用并发执行).
所以这个问题就像是流水线一样,第一个进程将
2~n依次写给第二个进程,第二个进程筛选非2倍数的数输出给第三个进程,第三个进程筛选非3倍数的数给第四个进程… 以此类推,单个阶段不一定要全部做完才交给后一阶段,完全可以像流水线一样进行。我们的目标是使用
pipe和fork来实现这样的流水线,我们将处理2~35的数字,进行素数筛。由于 xv6 的文件描述符和进程数量有限,第一个进程可以在35时停止。
使用wait来保真先后顺序,父亲之后才是孩子.在每一个管道的最后一端加入-1,代表管道内容已经结束了.
整体代码,蠡口刷多了,写起来不是会很费力的.读取老的管道,同时把数字写入到新的管道,创建新进程调用新的管道作为输入,注意也要在最后加入-1作为结尾
1 |
|
1.5.5find (moderate)
实现查找功能
- Look at user/ls.c to see how to read directories.
- Use recursion to allow find to descend into sub-directories.
- Don’t recurse into “.” and “..”.
- Changes to the file system persist across runs of qemu; to get a clean file system run make clean and then make qemu.
- You’ll need to use C strings. Have a look at K&R (the C book), for example Section 5.5.
- Note that == does not compare strings like in Python. Use strcmp() instead.
- Add the program to
UPROGSin Makefile
提示是要我们区看ls的实现,ls把通过switch来对不同的来做判断,我们的现在要求就是根据判断末尾是不是要查找的目标,来进行输出.那么这一个题目就是变成字符串的截取题目.因为对c不是很熟.所以对这个题的代码卡了很久.char *a=p.a=a+strlen(a).这个意思是把a得到位置移动到最末尾,通过这样就变成截取字符串的操作.
- 首先对与目标我们加上/,因为每一个文件都是/a/a/b这样的
- 然后我们使用ls一样的测策略,对于文件,移动到和目标文件一样长的地方,看他们想不想等,相等就进行输出
- 对于文件夹,我们使用递归,但是对于/..还有/.这个文件夹我们就不在进行递归
1 | // Directory is a file containing a sequence of dirent structures. |
文件夹的数据结构
实现代码
1 |
|
2.lab syscall
2.2 用户态,核心态,以及系统调用 · 6.S081 All-In-One (dgs.zone)
操作系统的作用是抽象系统同资源,最基本的目的就是互不影响程序,当一个程序出现问题不会影响下一个程序.所以系统管理员是操作系统,他与硬件打交道.
2.2用户态,核心态,以及系统调用
用户态和和心态,和心态就是直接与硬件打交道的
核心态可以使用特权指令,用户通过条用内核函数的程序,把用户态转移到和心态,然后 在内核指定的路口,进入内核(ecall函数)需要写entry(write),然后通过设置一个数字作为这个函数的映射,内核太调用这个数字实际对那个内核里面的函数来实现方法
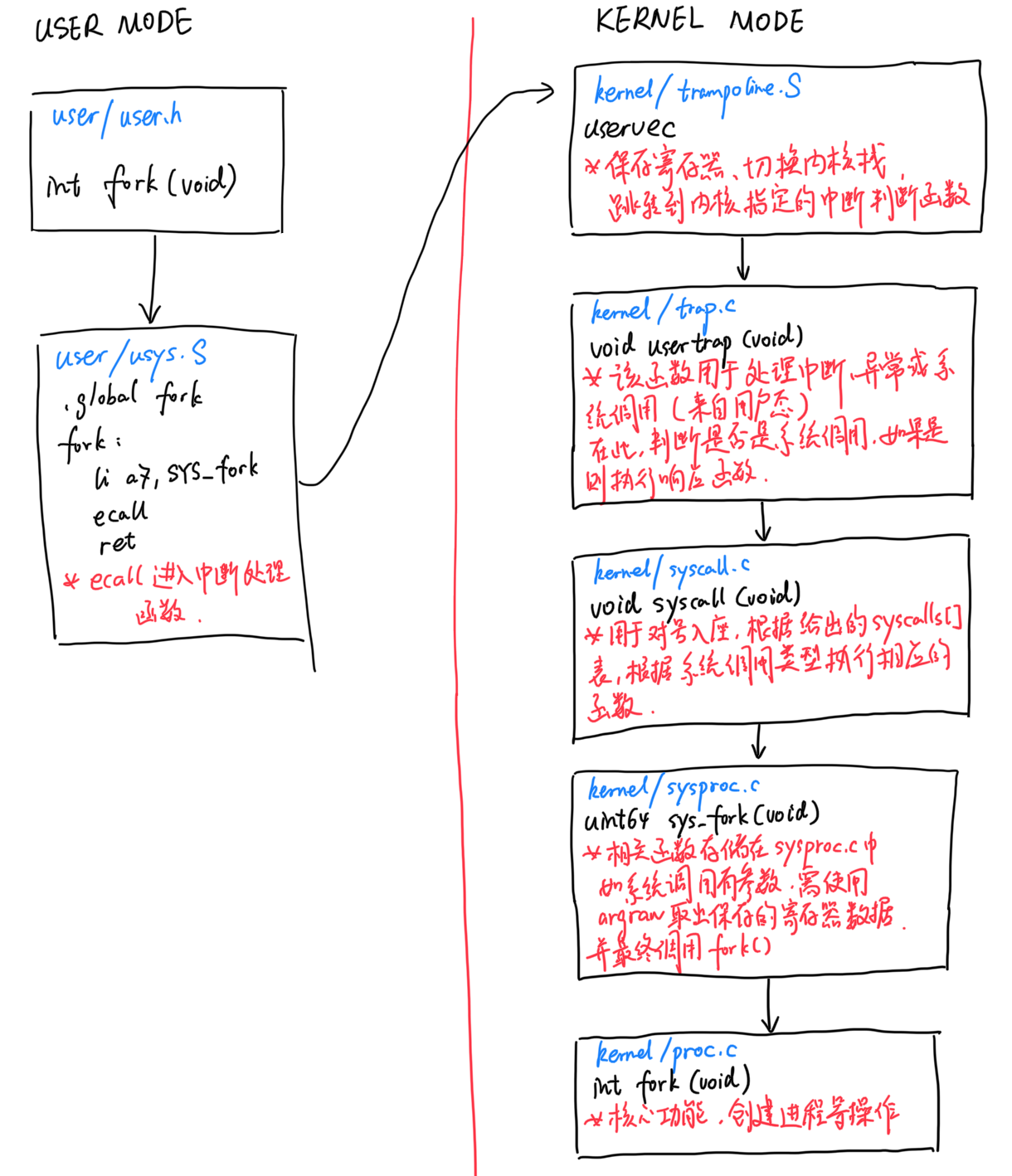
syscall调用sysproc实际方法
2.3内核组织
分为大内核还有小内核,大内核就是和Windows差不多,所以的硬件功能都已经实现,小内核就是自己要实现文件这中内核操作,通过组合操作.
2.4进程
进程都有自己的结构体,有自己的状态,还有自己的页表(页表,就是一个进程的虚拟地址空间)
2.5实验
2.5.1System call tracing (moderate)
实现追踪功能,然后追踪的进程的mask是这样得到 trace(1 << SYS_fork),这个参数可以通过argint得到
- Add
$U/_traceto UPROGS in Makefile- Run make qemu and you will see that the compiler cannot compile
user/trace.c, because the user-space stubs for the system call don’t exist yet: add a prototype for the system call touser/user.h, a stub touser/usys.pl, and a syscall number tokernel/syscall.h. The Makefile invokes the perl scriptuser/usys.pl, which producesuser/usys.S, the actual system call stubs, which use the RISC-Vecallinstruction to transition to the kernel. Once you fix the compilation issues, run trace 32 grep hello README; it will fail because you haven’t implemented the system call in the kernel yet.- Add a
sys_trace()function inkernel/sysproc.cthat implements the new system call by remembering its argument in a new variable in theprocstructure (seekernel/proc.h). The functions to retrieve system call arguments from user space are inkernel/syscall.c, and you can see examples of their use inkernel/sysproc.c.- Modify
fork()(seekernel/proc.c) to copy the trace mask from the parent to the child process.
给定的提示,我们直接运行make是无法编译成功的.提示是因为无法编译trace.c,因为这个给用户态的功能trace在内核态没有对应实现,我们需要实现.首先就是在userh里面添加trace功能(申明,系统提供的api).之后区usys添加入口,这是上面的陷入,然后添加一个数值在syscall
because the user-space stubs for the system call don’t exist yet: add a prototype for the system call to
user/user.h, a stub touser/usys.pl, and a syscall number tokernel/syscall.h. The Makefile invokes the perl scriptuser/usys.pl, which producesuser/usys.S, the actual system call stubs, which use the RISC-Vecallinstruction to transition to the kernel.
尽管添加了之后,你还是没有办法实现,因为你要实现systrace功能在sysproc里面,我们需要把追踪的进程的掩码设置成传入的参数,通过argint得到mask,之后对于该进程创建的子进程,我们也许奥把掩码设置成先对应的mask(复制操作,只需要更改fork的逻辑就行),最后我们把掩码一样的在syscall里进行输出.
这个题的主要重点,就是让我们了解到系统调用的流程,首先是在user里面注册系统调用函数,然后通过entry进行陷入这个函数,之后调用特殊的数值,来作为系统调用的参数.然后我们在sysproc具体实现这个功能
主要 的流程就是上图所示
所以,需要有一种方式能够让应用程序可以将控制权转移给内核(Entering Kernel)。
在RISC-V中,有一个专门的指令用来实现这个功能,叫做ECALL。ECALL接收一个数字参数,当一个用户程序想要将程序执行的控制权转移到内核,它只需要执行ECALL指令,并传入一个数字。这里的数字参数代表了应用程序想要调用的System Call。
ECALL会跳转到内核中一个特定,由内核控制的位置。我们在这节课的最后可以看到在XV6中存在一个唯一的系统调用接入点,每一次应用程序执行ECALL指令,应用程序都会通过这个接入点进入到内核中。举个例子,不论是Shell还是其他的应用程序,当它在用户空间执行fork时,它并不是直接调用操作系统中对应的函数,而是调用ECALL指令,并将fork对应的数字作为参数传给ECALL。之后再通过ECALL跳转到内核。
下图中通过一根竖线来区分用户空间和内核空间,左边是用户空间,右边是内核空间。在内核侧,有一个位于syscall.c的函数syscall,每一个从应用程序发起的系统调用都会调用到这个syscall函数,syscall函数会检查ECALL的参数,通过这个参数内核可以知道需要调用的是fork(3.9会有相应的代码跟踪介绍)。


- 在makefile进行注册
- 在user里面进行注册函数trace在sys里面进行进入entry
- 之后在syscall里面进行设置特殊的数值
- 然后调用这个sys_trace,之后在sysproc里实现(思路就是调用新的trace函数)
- trace函数就是把当前mask传给当前进程
- 然后在syscall调用,调用结束后.我们来对这个掩码做比较,相同就进行输出
1 | uint64 sys_trace(void) { |
这个trace函数还需要在defs进行申明,不然没发实现
1 | int trace(int mask) { |
对fork的修改,就是把父进程的mask传授那个给子进程
1 | // Create a new process, copying the parent. |
最后根据提示,我们在这里进行符合的输出
The 32 is
1<<SYS_read. In the second exam
他的逻辑就是把这个给进程进行移动系统的位数,所以我们只要一回来,然后与1,还是1,就说明这个是需要最终的,我们就进行输出
1 | if(p->mask >> num & 1) { |
1 | void |
3.lab pgtble
3.1基础知识
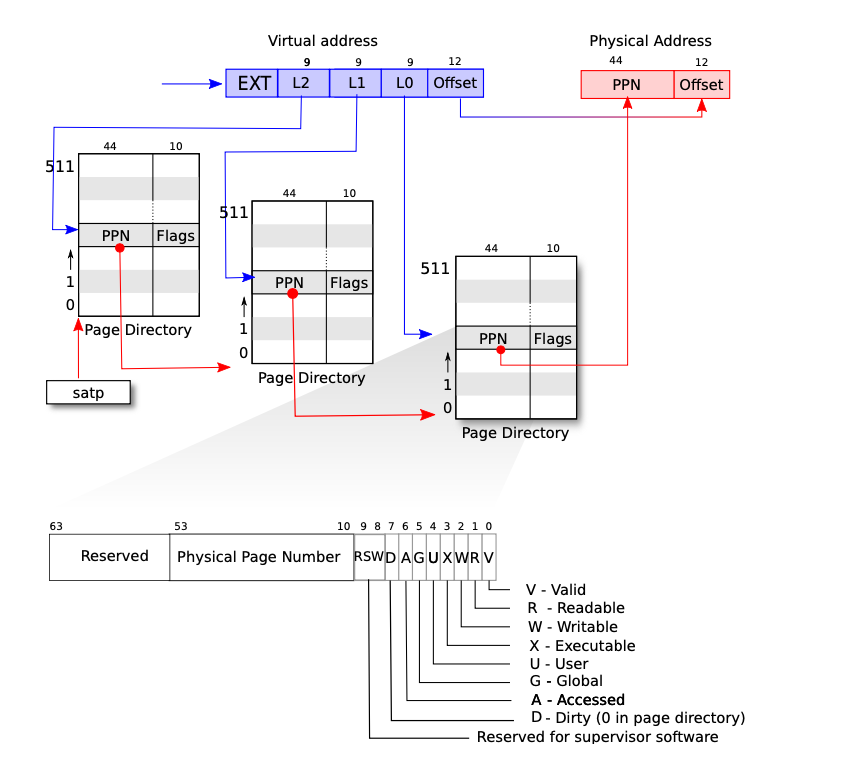
虚拟地址,通过页表来获取得到ppn(页表项),之后通过页表项目+offset得到最后的物理低值.这是一个三级页表,我没得到的前面两个ppn是下一个页面的地址.转化教程如下walk,让hi偶我们再看每一个pte是不是有效,获得pte使用的全相联,直接把这个虚拟地址进行映射到页表上面,最终与1ff想与,就是在512个里面找到是那一项
1 | pte_t * |
初始化流程
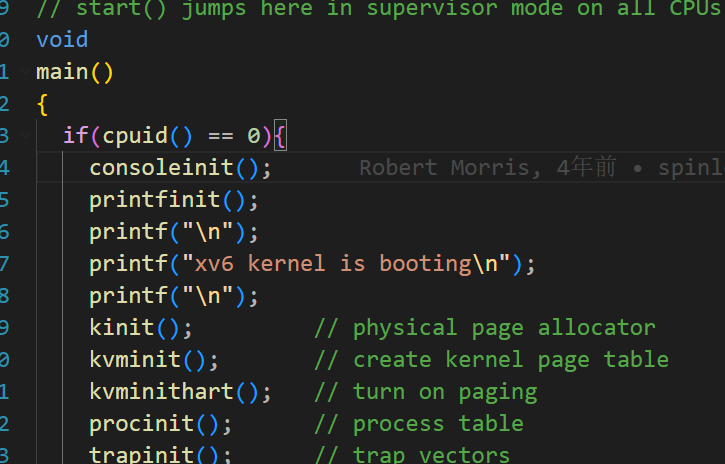
首先kinit是初始化锁,之后的kvmint初始化内核页表
1 |
|
主要看kvmake的,她的作用就是映射pa,与设备在内存的地址上面
1 | // add a mapping to the kernel page table. |
主要使用的map来进行操作,map就是设置映射最底层的实现了,参数分别为页表地址 pagetable,虚拟地址 va,映射大小 sz,物理地址 pa 和访问标志位 perm:
代码的含义:对虚拟地址首先下面对齐,结尾的扼要进行最下面的页面对齐
使用walk返回的值是一个地址,还需要*pte才是最后的值,返回的是物理地址.然后在使用 *pte = PA2PTE(pa) | perm | PTE_V;填入值
用户地址基础知识
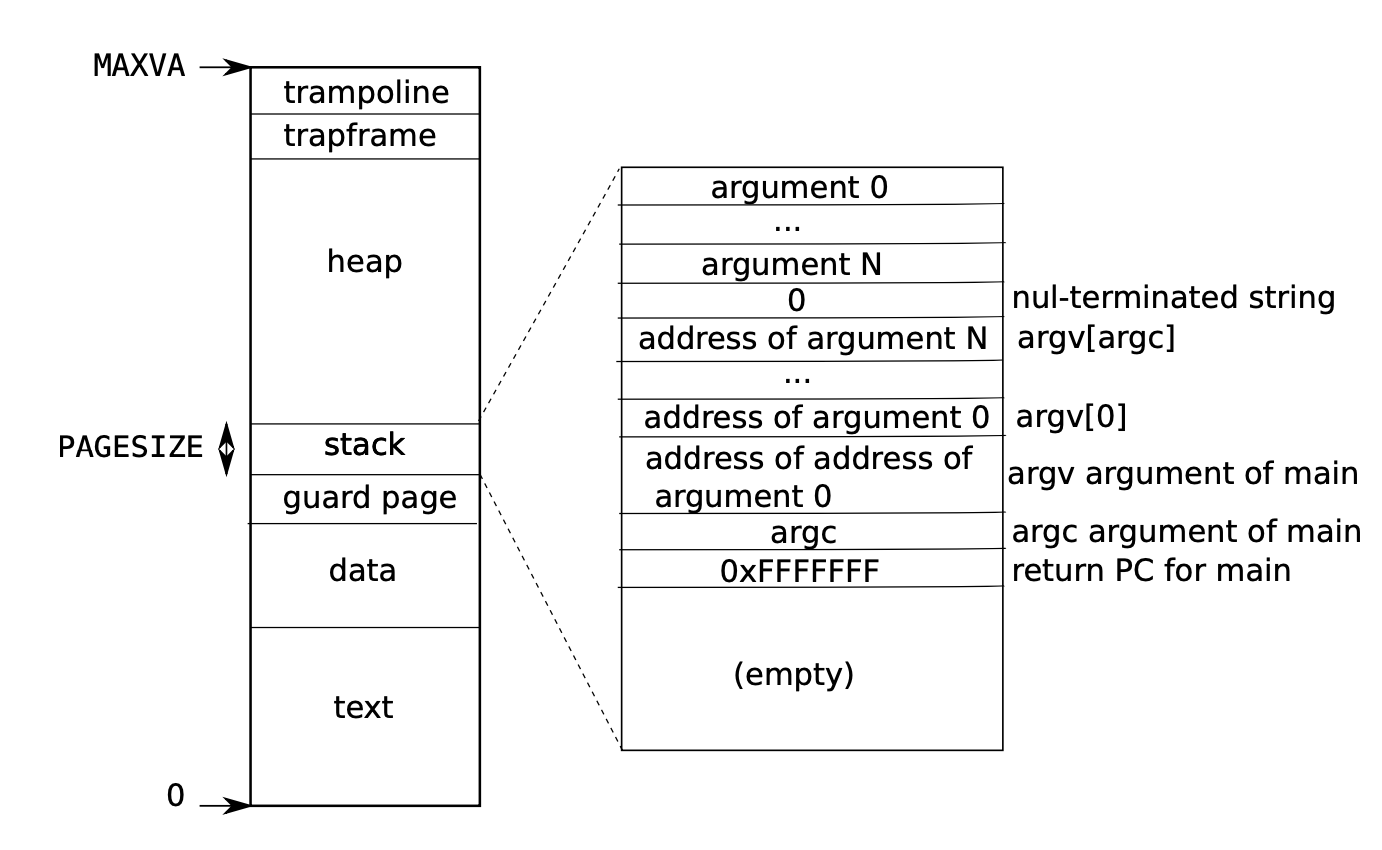
构建第一个用户程序
1 | // Set up first user process. |
对用户程序分配pagetable,epc,sp,状态,重点看alloc
1 | // Look in the process table for an UNUSED proc. |
通过查找 空闲的来进行分配
看用户页表的实现
1 | // Create a user page table for a given process, |
保留两个空间一个是trapframe(陷入的时候用的),然后放入到页表里面
3.2实现系统调用的加速
要求和提示
在这个部分中,我们要通过调整页表的映射来实现对特定的系统调用的加速。
在部分操作系统(例如 Linux 中),会使用用户空间和内核空间之间的一块只读区域用来进行数据共享,以此来达到加速特定的系统调用的目的,这样就消除了与内核交互产生的开销。在本部分中,我们将实现对 getpid 系统调用的优化。
当一个进程被创建时,我们需要将一个只读的内存页映射到 USYSCALL 上,其中 USYSCALL 是一个虚拟内存地址,见 kernel/memlayout.h。在该内存页上我们需要存储一个叫 struct usyscall 的结构体,见 kernel/memlayout.h,然后将其初始化使其存储当前进程的 PID。下面是 memlayout.h 的节选部分:
1 | C |
在这个 Lab 中,系统在用户空间部分已经提供了 ugetpid(),并会自动使用 USYSCALL 的映射,ugetpid 函数就是我们测试时的函数,为了使得他工作正常我们需要完成相关修改。这段见 user/ulib.c:
1 | C |
相关提示:
- 可以在
kernel/proc.c下的proc_pagetable中处理内存映射问题。 - 注意处理访问标志位使得该内存页对用户空间来说是只读的。
- 了解
mappages()的使用方法会很有帮助。 - 不要忘记在
allocproc()中分配和初始化内存页。 - 确保在
freeproc()中正确地释放了内存页。
大致的意识就是要求我们使用用户空间和内核空间之间的一块只读区域用来进行数据共享,以此来达到加速特定的系统调用的目的,这样就消除了与内核交互产生的开销。
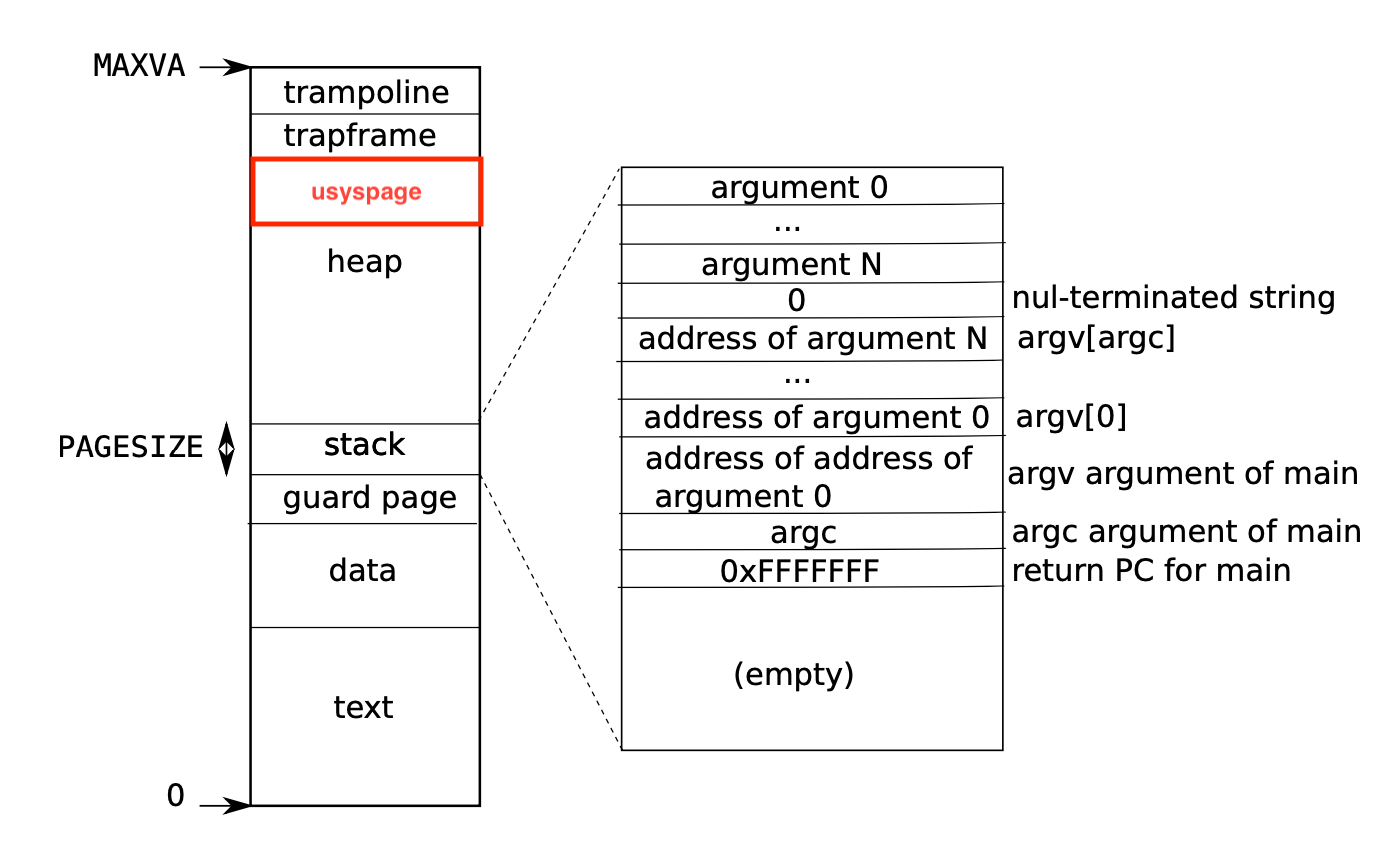
要求我们在usyspage这个里面进行设置我们的信息都存放在这个空间里面
根据我们上面的基础知识,我们知道页表初始化**,实在proc_pagetable(p);**这个函数里面,我们在这里进行映射usys这个地址到页表.
和trapoframe一样的流程,分配之后,然后才是分配页表
1 | // Allocate a trapframe page. |
1 | if (p->pagetable) proc_freepagetable(p->pagetable, p->sz); |
注意到释放过程,调用页表,那么页表项,我们也要释放
1 | uvmunmap(pagetable, USYSCALL, 1, 0); |
3.3实现页表打印
要求和提示
在本部分中,我们需要将 RISC-V 的页表可视化,也就是实现一个页表内容的打印功能,作为后续调试的辅助工具。
我们需要定义一个叫做 vmprint() 的函数,这个函数应当传入一个类型为 pagetable_t 的参数,也是页表的指针,然后将页表的全部有效信息打印出来。题目要求在 kernel/exec.c 下的 exec() 中,在最后的 return argc 前加入一行(疯狂暗示,喂到嘴巴里):
1 | C |
来实现对第一个进程的页表的打印。
题目中给出了示例,当第一个进程刚完成 exec() 执行了 /init 时的页表状态:
1 | PLAINTEXT |
相关提示:
- 可以把
vmprint()放在kernel/vm.c里面 - 记得使用
kernel/riscv.h最后添加的宏定义,包括但不限于PTE2PA等 - 强烈建议参考
vm.c文件中的freewalk函数(疯狂暗示,喂嘴巴里了) - 记得在
kernel/defs.h中定义vmprint函数,以便在exec.c中成功调用 - 在
printf中使用%p来打印完整的 16 进制 64 位地址和 PTE 信息
这个很明显就是递归的效果,我们参考freewalk,首先得到page,之后根据二级页表得到页表项,再继续递归
1 | void pgtblprint(pagetable_t pagetable, int depth) { |
3.4查询内存页访问情况
要求和提示
一些垃圾回收器可以根据内存页被访问情况的信息来进行工作。
在本部分中,我们将主要考虑为 xv6 实现一个新的功能,也就是检测用户空间的内存访问情况,并将信息返回给用户空间。我们需要通过检查 RISC-V 页表中的 A 标识位来实现,RISC-V 硬件每当尝试解决 TLB 未命中问题时,访问内存页的时候就会在页表中将对应 PTE 的标志位置为有效。
我们的目标是实现一个叫做 pgaccess 的系统调用,以此来查看哪些内存页被访问过了。这个系统调用需要传入三个参数,第一个参数是开始的要查看的用户空间内存页地址,第二个参数是需要查看的内存页数量,最后传入的是一个用户地址空间,好让我们将结果写到用户地址空间,结果以 bitmask 的形式存储,每一位和各个内存页一一对应,第一个内存页对应最小的比特位。
相关提示:
- 考虑在
kernel/sysproc.c下实现sys_pgaccess()系统调用主要功能。 - 需要使用
argaddr()和argint()来获取系统调用传入的参数,这一块可以详见上次的 Lab syscall: System calls。 - 由于我们需要将结果返回给用户态的地址,因此有必要使用内核态中的临时缓冲区进行结果的处理,然后使用
copyout()函数将结果复制到用户态,这段也可见 Lab Syscall 中相关内容。 - 可以设置扫描的内存页数上限。
- 在
kernel/vm.c下的walk()函数会对找到正确的 PTE 很有帮助。 - 需要在
kernel/riscv.h中额外定义一下PTE_A,也就是访问标记的比特位。(不敢相信他们居然原来没有加) - 确保在扫描内存页结束后将标志位
PTE_A清零,不然下次扫描这个页的时候你看到标志位就乱了,不知道有没有被访问过了。 - 在调试页表的时候可以使用
vmprint(),活学活用了属于是。
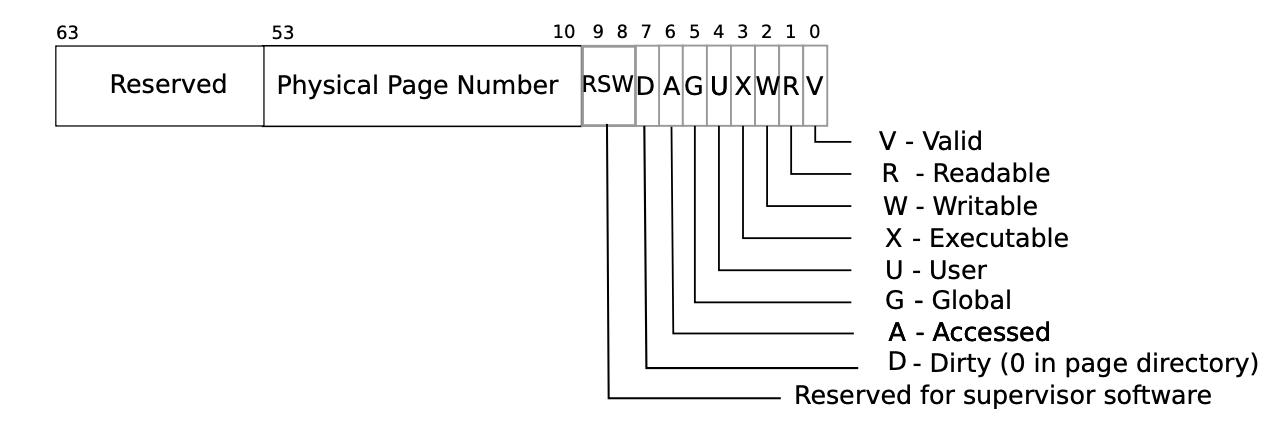
数,第一个参数是开始的要查看的用户空间内存页地址,第二个参数是需要查看的内存页数量,最后传入的是一个用户地址空间,好让我们将结果写到用户地址空间,结果以 bitmask 的形式存储,
参照这个图,我们自己来进行设置access
1 |
可以参照这个代码块
- 首先arg获得参数
- 然后是指读取条目数
- 之后就是对地址来求pte,看pte之后来进行清楚
1 |
|
3.5总结
终于填完所有的坑了,重点就是包含xv6的启动过程,首先kvinit(lock),之后就是kvm.内核启动,包括空间分配还有内核启动时候页表的操作,着重的讲解是如何使用pte来得到物理地址,使用walk可以得到当前va的pte地址,通过指针可以得到值,然后使用maparg来进行映射
- 页表简介
- 内核态简介
- 用户空间简介
4.lab trap
实验
4.1回答问题
Read the code in call.asm for the functions g, f, and main. The instruction manual for RISC-V is on the reference page. Here are some questions that you should answer (store the answers in a file answers-traps.txt):
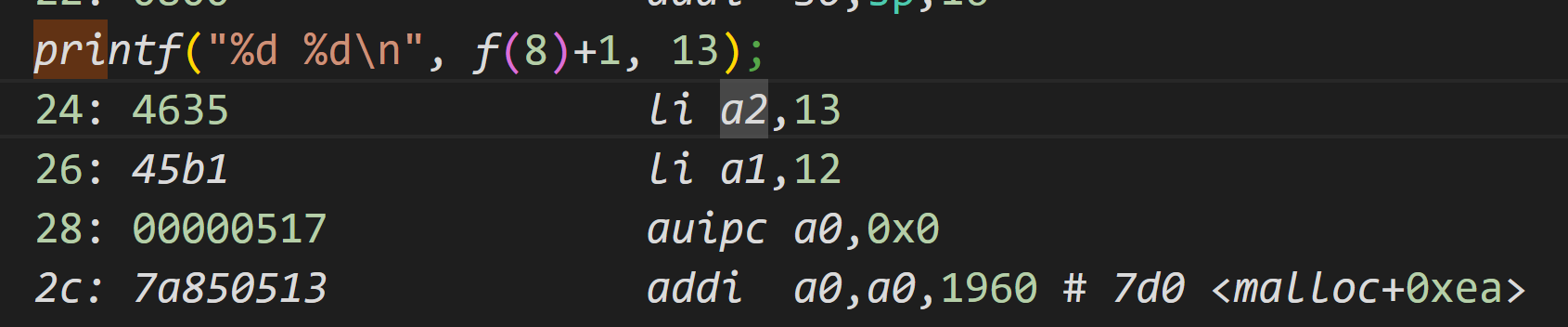
Which registers contain arguments to functions? For example, which register holds 13 in main’s call to
printf?
a2
Where is the call to function
fin the assembly code formain? Where is the call tog? (Hint: the compiler may inline functions.)
显的可以看到在 0x26 位置,程序直接将 12 写入了 a1 寄存器的位置(也就是第二参数 f(8)+1 的位置),在处理完所有的寄存器参数后直接就调用了 printf。那只有一种解释,就是编译器直接计算出了 f(8)+1 的结果是 12,主函数中并没直接调用这两个函数
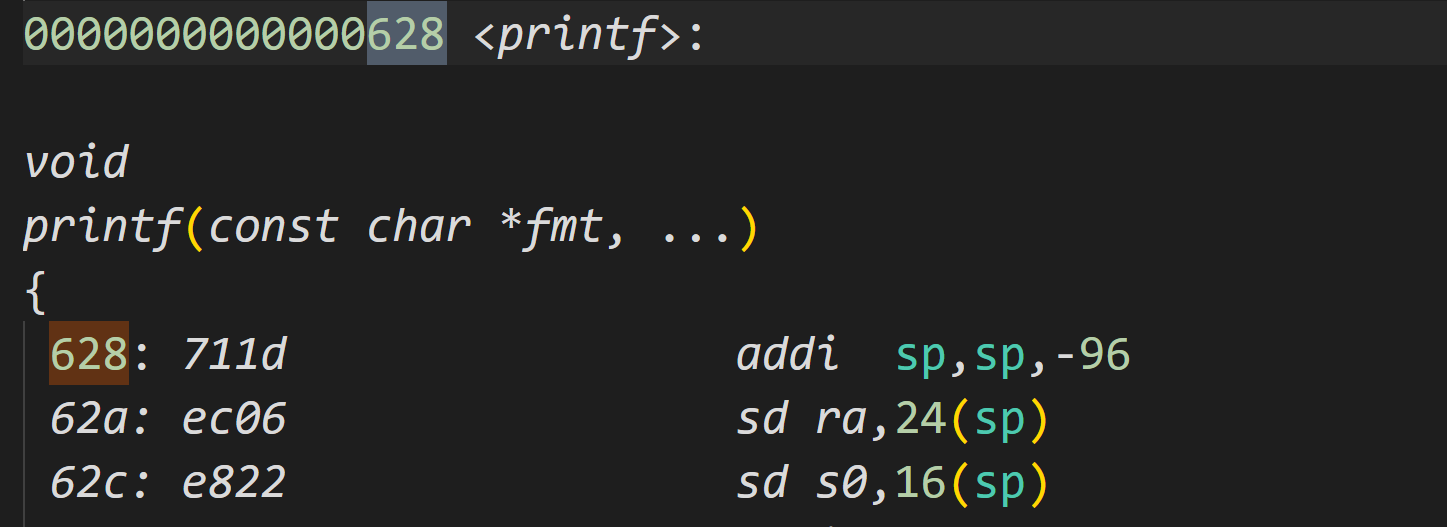
At what address is the function
printflocated?
根据提示他在628,我们直接收地址628

What value is in the register
rajust after thejalrtoprintfinmain?
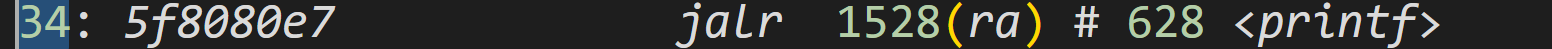

34是pc地址,后面的是指令,手册的pc+4,就是34+4=38是ra
Run the following code.
2
3
printf("H%x Wo%s", 57616, &i);
What is the output? Here’s an ASCII table that maps bytes to characters.
The output depends on that fact that the RISC-V is little-endian. If the RISC-V were instead big-endian what would you set to in order to yield the same output? Would you need to change to a different value?
i``57616Here’s a description of little- and big-endian and a more whimsical description.
57616十六进制是e110
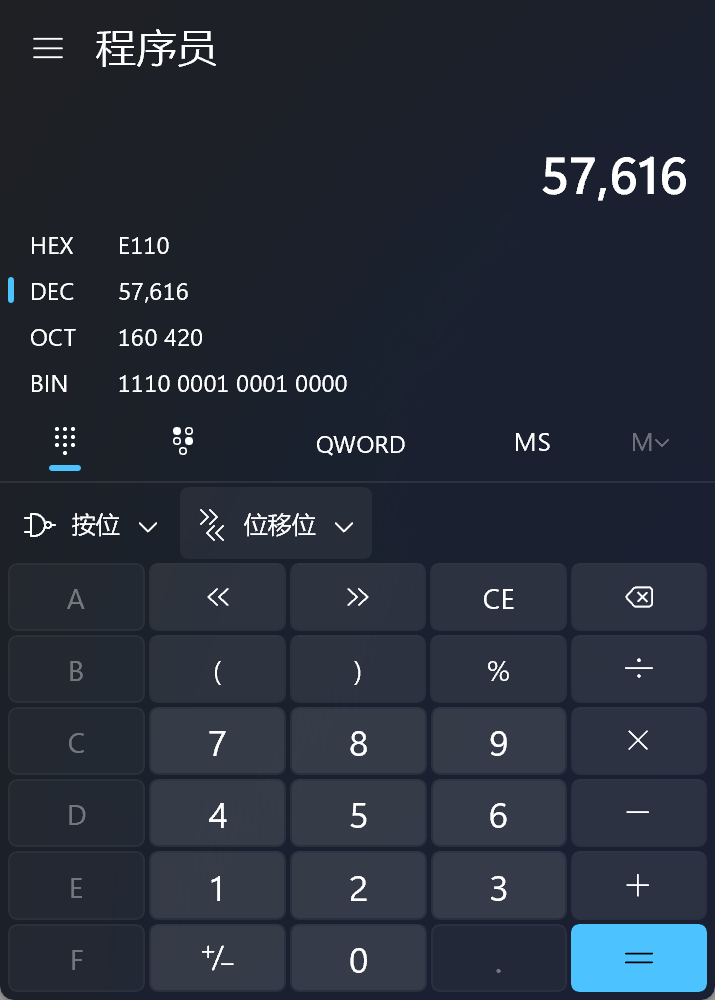
下一个是小段对齐(就是最开始第一位是末尾2个字节,最后的才是开始)
In the following code, what is going to be printed after ? (note: the answer is not a specific value.) Why does this happen?
'y='
a2寄存器没有值,随便产生
4.2函数调用栈打印
要求和提示
我们在代码调试的过程中为了定位错误的位置,经常需要使用到函数的调用栈打印。当错误发生时,会打印出一系列之前的函数调用信息。
在这里要求我们需要在 kernel/printf.c 下实现函数 backtrace(),并在 sys_sleep 中插入对此函数的一个调用。当我们在终端中调用 bttest 测试时,该命令会调起 sleep 系统调用,从而触发打印,运行 bttest 时打印结果示例为:
1 | PLAINTEXT |
在 bttest 退出了 QEMU 之后,在终端下,我们也可以使用 addr2line 命令来将指令地址转化为具体的代码位置,例如我们使用指令 addr2line -e kernel/kernel:
我们的目标是从顶部开始遍历各个栈帧,并将各个栈帧中保存的返回地址打印出来。(讲道理感觉做个 -4 打印调用函数的地址可能会更直观一点,但是他说是就是吧)
相关提示:
需要在
kernel/defs.h中添加backtrace的声明,使得我们可以在sys_sleep下调用backtrace。GCC 编译器将当前执行的函数的栈帧指针 frame pointer 存储在
s0寄存器中,为此我们需要在kernel/riscv.h下加入代码:1
2
3
4
5
6
7
8C
static inline uint64
r_fp()
{
uint64 x;
asm volatile("mv %0, s0" : "=r" (x) );
return x;
}以方便我们在
backtrace中调用来读取栈帧的底部地址。P.S.
sp和fp是典型的堆栈寄存器,用来标注当前栈帧的底部和顶部地址,由于我们在描述的时候对顶部和底部往往有自己的理解,因为栈地址是向下增长的,这里还是放一张图会比较好: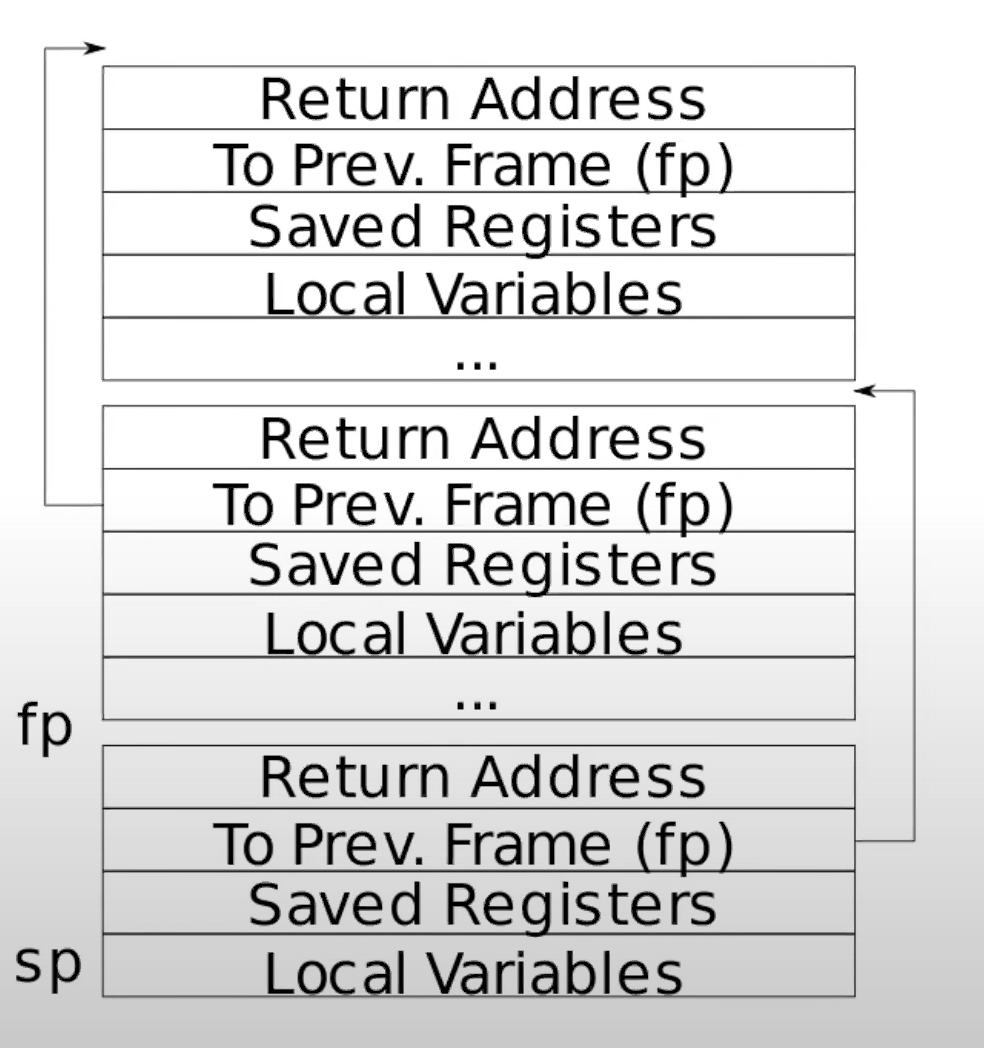
由刚才贴出的图可见,注意到当前函数的返回地址和当前的
fp存在一个-8的地址偏移量,上一个栈帧的fp保存位置和当前的fp存在一个-16的偏移量。在 xv6 中,操作系统内核会为每个栈分配一个页面的空间,并地址对齐。因此我们可以使用
PGROUNDDOWN(fp)和PGROUNDUP(fp)来寻找栈所在页面的顶部和底部地址,PGROUNDDOWN和PGROUNDUP的定义可以看下kernel/riscv.h:1
2
3
4
5
函数调用栈的实现,我们可以通过这个图可以看到每一个栈的大小是不固定,因为参数可能不一样,但是返回地址,还有上一个节点的地址是ra,和上一个fp是固定的,都是当前的fp-8,还有fp-16,得到这两个的值
- 因此我们只需要进行递归地道道当前fp,是不是最上面的地址(pgup(fp))(这是第一个fp),就代表结束
1 | void backtrace(void) { |
4.3实现定时器
要求和提示
在本部分中,我们将为 xv6 添加一个新的功能,使得当一个进程使用 CPU 时间的时候周期性的发出警告。这种功能对于想要限制它们占用多少 CPU 时间的计算型进程,或者对于想要计算但又想采取一些定期行动的进程,可能是很有用的。更广泛地说,我们将实现一个原始形式的用户级中断 / 故障处理程序;例如,我们可以使用类似的东西来处理应用程序中的页面故障。我们需要通过 alarmtest 来完成该部分。
我们需要在 xv6 中添加一个新的系统调用 sigalarm(interval, handler),例如当程序调用 sigalarm(n, fn) 的时候,那么接下来程序每消耗 n 个 ticks 的 CPU 时间后,内核应该调用 fn。当 fn 成功返回时,程序应当继续不受影响的运行,这部分由需要添加的系统调用 sigreturn 负责完成。如果应用程序调用 sigalarm(0, 0),内核应该停止产生周期性的调用。
P.S. 在 xv6 中,tick 是一个相当随意的时间单位,由硬件定时器产生中断的频率决定。
alarmtest 的相关代码在 user/alarmtest.c 中可见,为了使得其能够被正确识别,我们需要将其加入到 Makefile 中,如果对这块已经有点不记得的小伙伴可以看看 Lab Utils,可能可以记起来。
由于 alarmtest 文件中使用了两个我们待实现的系统调用 sigalarm 和 sigreturn,务必将系统调用正确添加,记不得的小伙伴可以再去看看 Lab Syscall… 后面也会继续提
在 alarmtest 中在 test0 调用了 sigalarm(2, periodic),要求内核每隔 2 个 ticks 强制调用 periodic(),然后尝试自旋一段时间。我们可以在 user/alarmtest.asm 中看到 alarmtest 的汇编代码,这可能对调试很有帮助。
正确运行 alarmtest 和 usertests 的示例结果如下:
1 | PLAINTEXT |
这块内容分为两部分完成,我们首先实现 test0,再实现 test1 和 test2。
对于 test0 而言,其功能是测试 handler 函数是否被正确执行了,首先我们需要修改内核代码使得内核可以跳转到用户空间中的 periodic 函数,从而打印出 "alarm!"。我们在这里暂时不考虑打印之后怎么处理,如果你在打印出 "alarm!" 程序直接 crash 也是完全正常的。以下是关于 test0 的相关提示:
请将
alarmtest.c加入 Makefile 中,使得其能够被正常编译。两个系统调用需要在
user/user.h中声明:1
2
3C
int sigalarm(int ticks, void (*handler)());
int sigreturn(void);你需要更新
user/usys.pl,kernel/syscall.h和kernel/syscall.c来使得alarmtest可以正确的触发sigslarm和sigreturn系统调用。这块不记得的可以看看 Lab Syscall。test0中对sys_sigreturn暂时没有要求,可以返回0完事。你的
sys_sigalarm()需要在kernel/proc.h下的proc结构体中开辟新的空间额外存储间隔时间和 handler 函数的指针。你需要跟踪从最后一次调用直到下一次调用,过去了(或者说还剩下)多少时间,因此我们也需要在
proc结构体中开辟额外的空间来实现。初始化proc结构体参数的方法详见kernel/proc.c下的allocproc()。每一次 tick 周期,硬件始终都会强制中断,这块的逻辑代码由
kernel/trap.c下的usertrap()实现。在
usertrap()下,如果我们要控制硬件定时器中断发生时的行为,例如修改proc中存储的时间参数,我们只需要关注如下代码下的改动:1
2C
if(which_dev == 2)请当进程有一个未完成的定时器时才可调用 handler 函数。注意到 handler 函数的地址可能是
0,例如在user/alarmtest.asm中,periodic位于地址0。请修改
usertrap()使得当进程的定时间隔过期时,用户进程可以执行 handler 函数。另外请思考,当在 RISC-V 上的陷阱返回到用户空间时,是什么决定了接下来用户空间代码开始执行的位置?为了方便使用 GDB 观察陷阱的运行,我们可以让 QEMU 只使用一个 CPU,例如运行如下代码:
1
2BASH
make CPUS=1 qemu-gdb在本阶段中,只要
alarmtest成功打印出"alarm!."即为成功
对于 test1 和 test2 而言,其功能主要是测试被中断的代码接下来是否能够继续运行。为了确保程序接下来能够继续正确的运行,我们需要在 handler 函数执行完毕时,返回至被定时器中断的代码位置,同时保证寄存器内容被正确的存储并恢复了。最后我们需要在每次计时结束后重置计时器的计数器,使得 handler 函数能不断的被周期调用。
我们假定如下的设计:用户空间的 handler 函数在结束时需要调用 sigreturn 系统调用,参考 user/alarmtest.c 的 periodic 函数。这意味着我们需要在 usertrap 和 sys_sigreturn 中进行修改,使得用户空间进程可以正确的继续执行下去。如下为关于 test1 和 test2 的相关提示:
- 为了保证被中断程序的正确运行,你需要保存和恢复寄存器。请思考一下,哪些寄存器需要你进行存储和恢复呢?
- 在
usertrap中需要向proc结构体中保存一些状态信息,以方便sigreturn正确返回到原先的代码位置。 - 禁止可重入的调用 handler 函数,在 handler 函数没有返回之前,内核不应当再次调起。关于这块的测试将在
test2中有所体现。
题解
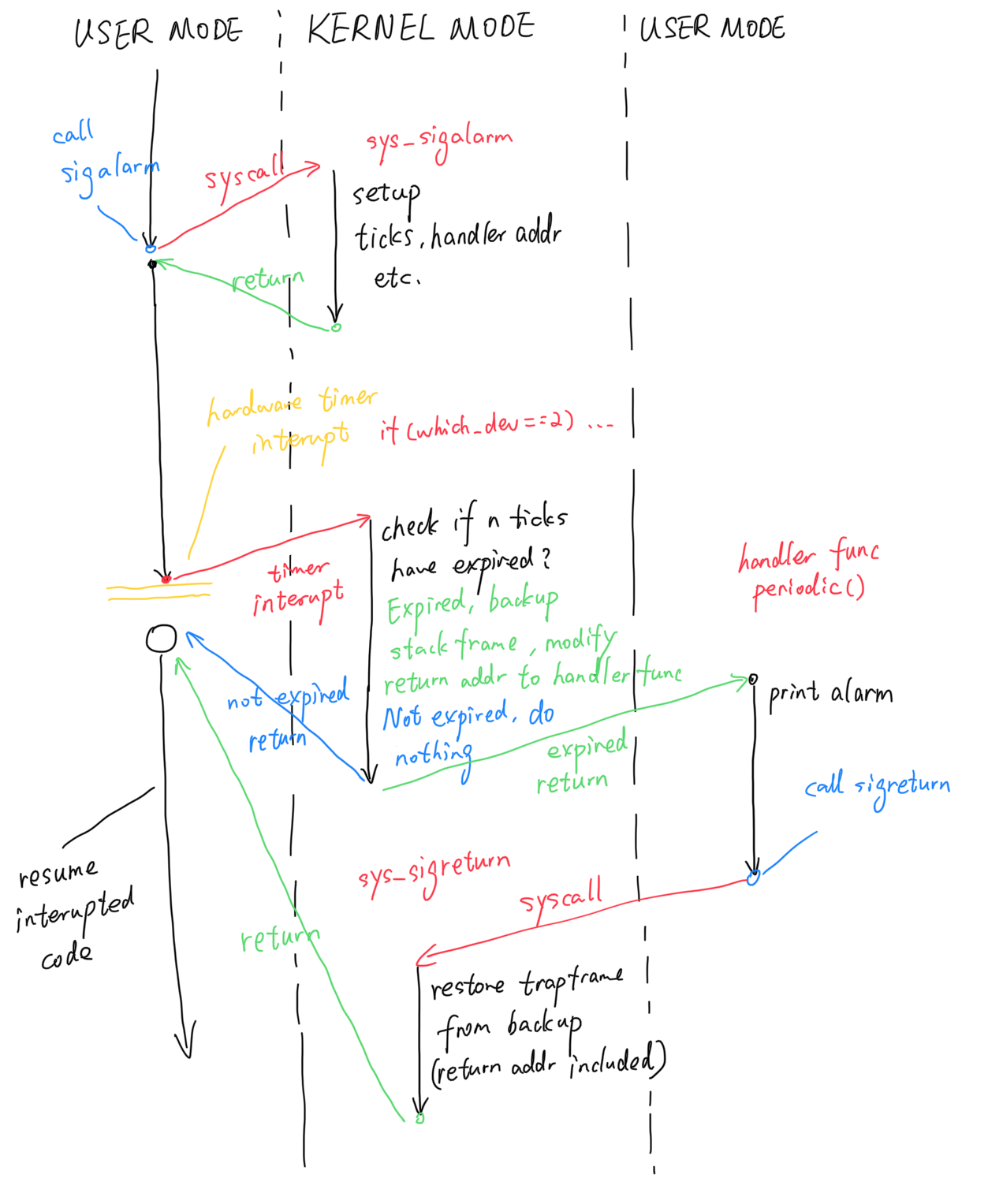
陷入流程:
- 首先是调用systemcall,我们首先设置handler,还有时间
- 之后就是始终的定时中断
- 我们首先可以在dev=2这个地方捕捉到中断信号,我们需要把当前运行pc设置成handler来进行处理,如果当时间满了的情况下
- 之后,这个中断结束,但是可能会被其他程序抢走,所以这个程序的trapframe也需要保存下来
让我们梳理一下题意
- 首先完成用户态到内核态陷入,之前的已经写过,跳过
- 需要我们在proc的结构体里面添加处理函数handler
- 距离下一次调用的时间也需要进行设置
- 然后userttrap下面的dev就是定时中断锁需要进行的操作
- 现在我们来回顾一下陷入流程
完成sys_sigalarm
添加下列参数到proc里面
p->alarm_interval = ticks;
p->alarm_handler = handler;
p->alarm_ticks_left = ticks;
主要就是获取参数,然后设置到proc里面
1 | uint64 sys_sigalarm(void) { |
完成trap陷入操作
每一次中断,我们都会让时间减少,而且还要看是不是已经运行了
所以需要lock参数,我们需要备份trapframe,按照之前的样子,所以还需要
backtrap,还有lock
1 | // give up the CPU if this is a timer interrupt. |
恢复操作
1 | int sigreturn() { |
4.4总结

总体流程
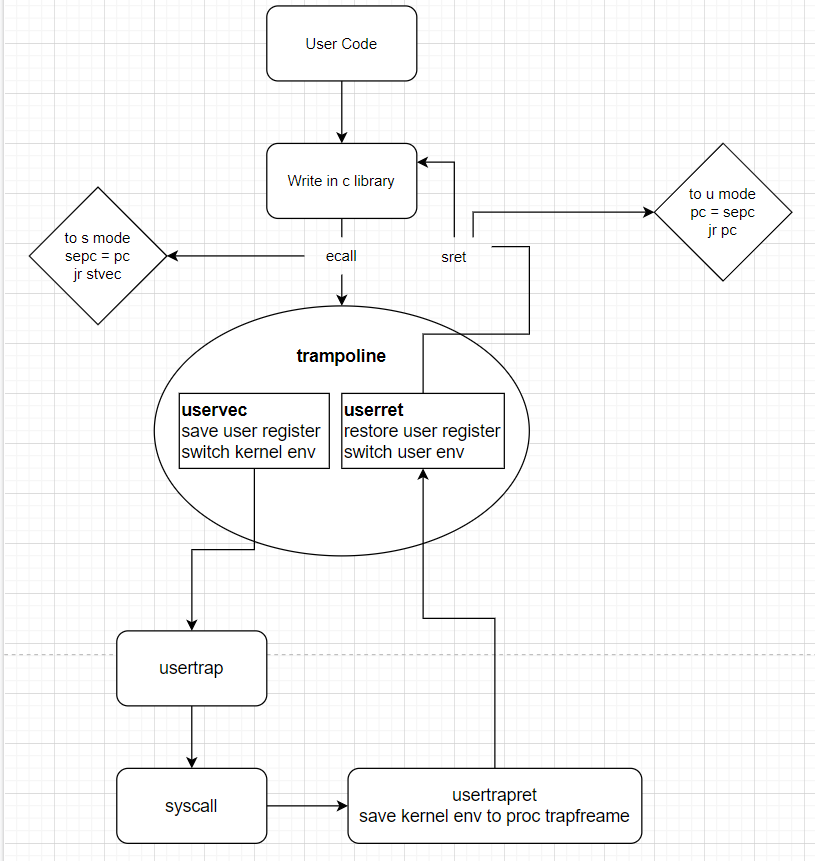
- 首先调用ecall
- 之后是uservec(内核执行的第一个程序,trampoline是一部分,保存页表)
- 然后才是转到c语言的usertrap,开始查看是什么类型的原因到内核态(trap,interupt还是page fault)
- 陷入之后是system call,调用实际的底层函数
ecall作用详解:
第一,ecall将代码从user mode改到supervisor mode。
第二,ecall将程序计数器的值保存在了SEPC寄存器。我们可以通过打印程序计数器看到这里的效果,
ecall跳转到stvec
在trampoline page详解:
- 修改vec的代码
- 保存寄存器等其他信息trapframe
主要就是保存你用户的页表
usertrap详解:
找到是什么类型,来进行对应出路i

sertrap函数的最后调用了usertrapret函数,来设置好我之前说过的,在返回到用户空间之前内核要做的工作
1 | void |
保存相关的内核信息到trapframe,然后再次进入到trampoline,进行恢复用户的页表

接下来的几行填入了trapframe的内容,这些内容对于执行trampoline代码非常有用。这里的代码就是:
-
存储了kernel page table的指针
-
存储了当前用户进程的kernel stack
-
存储了usertrap函数的指针,这样trampoline代码才能跳转到这个函数(注,详见6.5中 ld t0 (16)a0 指令)
-
从tp寄存器中读取当前的CPU核编号,并存储在trapframe中,这样trampoline代码才能恢复这个数字,因为用户代码可能会修改这个数字
实际上,我们会在汇编代码trampoline中完成page table的切换,并且也只能在trampoline中完成切换,因为只有trampoline中代码是同时在用户和内核空间中映射
5.cow
写时候分配,大致意识fork的时候,不进行分配,使用与父亲的一起共享的内存,当这篇内存要写入的时候,出发page fault,在进行分配,分配主要包括,给内存释放权限,还有重新进行开辟一个新空间
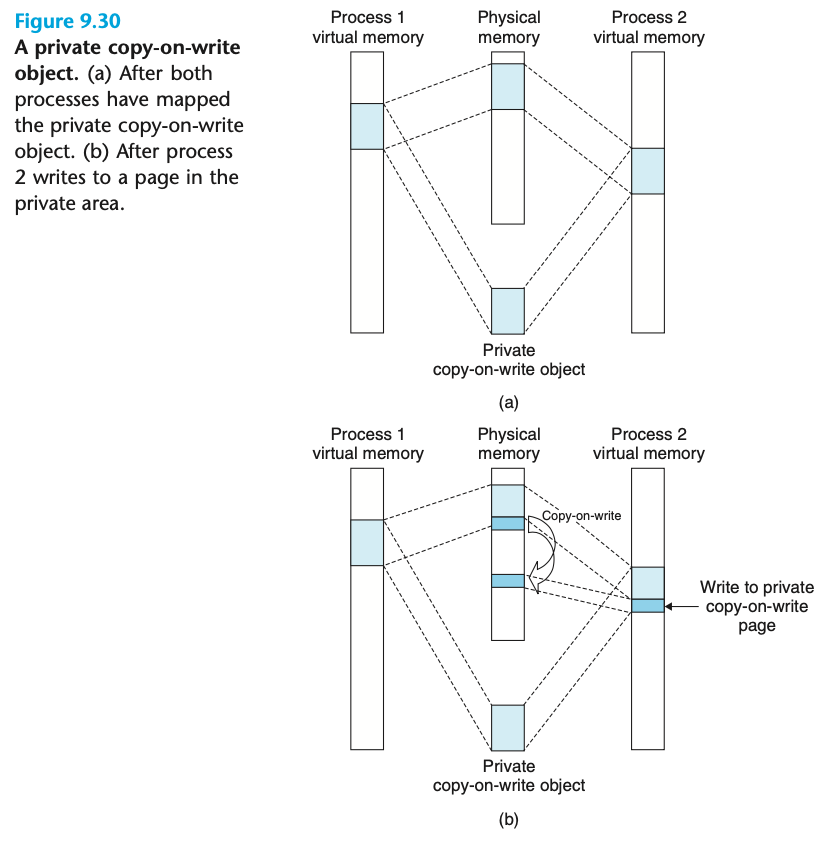
5.1实现 COW 下的 fork
要求和提示
在本部分中,我们的任务是在 xv6 操作系统中实现一个写时复制的 fork。完成的代码需要通过 cowtest 和 usertests 测试。cowtest 中的相关测试样例详见 user/cowtest.c。
例如,如果我们对 xv6 操作系统一开始什么都没做修改,就直接执行 cowtest,我们会得到如下结果:
1 | PLAINTEXT |
这是因为在 simple 测试样例中,它分配了超过一半的可用物理内存空间,随后调用 fork。在没有实现 COW 的 xv6 下,操作系统会采取 eager 策略,立即为子进程创建对应用户空间并着手复制,这会直接导致物理内存空间的耗尽。
为了实现 COW 我们要在以下几处完成修改:
- 修改
kernel/vm.c下的uvmcopy()函数,我们需要共享父进程和子进程的用户空间,而非重新分配新的内存。此外,我们还需要将子进程和父进程的 PTE 置为只读,以触发缺页中断 page fault。 - 修改
kernel/trap.c下的usertrap()函数,使得内核可以正确的判断出发生了缺页中断 page fault。一旦内核识别出在一个 COW 内存页上发生了缺页中断,就需要使用kalloc()开辟新的内存页,并将原内存页的数据拷贝到新的内存页上,并设置新的映射关系,将 PTE 下的可读PTE_W置位。 - 我们需要确保当该物理页面最后的 PTE 引用 ref count 清零了才可将其进行释放。当
kernel/kalloc.c下的kalloc()分配该内存页时我们就将其 ref count 设置为1,每当有fork操作使得子进程共享该内存页时我们就将 ref count 加一,同理每当一个进程将对应映射关系从其页表中删除时,我们就要将 ref count 减一。只有当 ref count 清零的时候我们才可以将当前内存页使用kernel/kalloc.c下的kfree()放置在空闲列表中。我们可以把这些计数的 ref count 放在一个固定大小的整数数组中,例如我们可以使用页面的物理地址除以4096来索引数组,然后给数组一个等同于kalloc.c中kinit()放置在空闲列表中页面的最高物理地址的元素数。 - 不要忘记修改
kernel/vm.c下的copyout(),来适应 COW 的内存页,因为可能有用户空间下的内存页暂未被分配,原先的copyout也会触发 page fault。
相关提示:
我们很有可能需要标记当前的 PTE 为 COW 内存页映射,因此我们可以使用 RSW(reserved for software)标识位来实现:
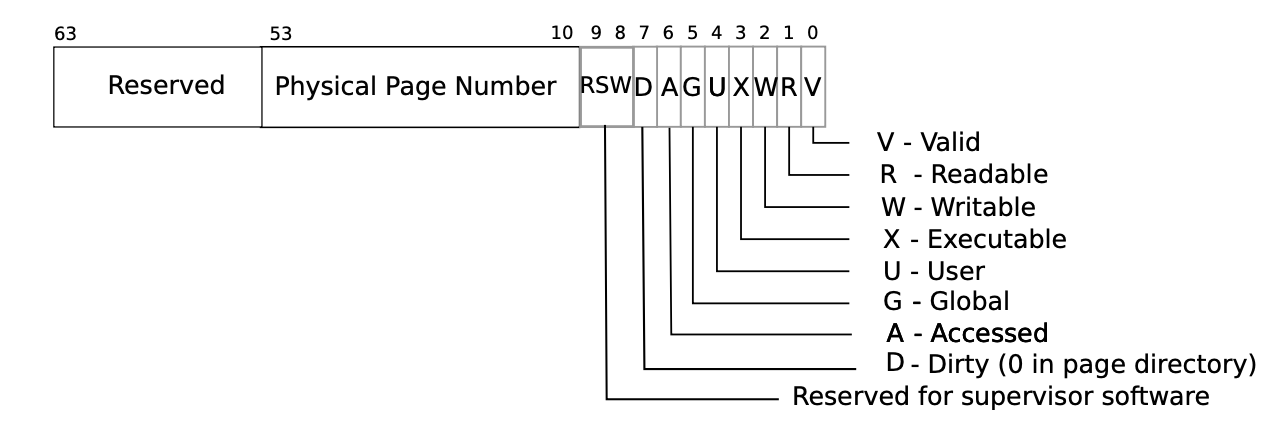
一些有用的宏和定义可以方便处理 PTE 的相关标识位,这些代码在
kernel/riscv.h的最后可以找到。如果 COW 下的缺页中断产生了,但是也没有足够的物理内存空间,那么进程应当被杀死。
题解
提示已经给了很多信息,我们把提示在进行翻译一遍
这个rsw标记需要我们自己手动来做
- 首先修改uvmcopy,不是分配,二十把这个新地址还是映射到同一个物理地址,之前的map函数,同时设置不能写,符号
- 然后修改trap,因为会出发page_fault,这样我们需要解开原来的映射,然后进行kalloc分配,新的还要加入写入权限**(注意,解开原来映射的时候,会消灭原始内存,因此需要引用计数)**
- 之后就是应用计数的相关设置
- 然后设置copy的配置
们可以把这些计数的 ref count 放在一个固定大小的整数数组中,例如我们可以使用页面的物理地址除以
4096来索引数组,然后给数组一个等同于kalloc.c中kinit()放置在空闲列表中页面的最高物理地址的元素数。
设置页面数组,来统计每一个页面使用的次数,当然还是要进行枷锁
1 | struct { |
刚开始就是初始化,维1此使用,之后就是设置++
1 | int refcount_add(uint64 va, int add) { |
之后就是freerange来开始设置
,因为他调用了kfree
1 | int refcount_add(uint64 va, int add) { |
首先是设置uvmcopy
1 | #define PTE_V (1L << 0) // valid |
设置维rsw,并且只能读取,还有进行映射地址,还有应用加一
1 |
|
我们在这里对这个物理页面进行加1此使用
通过这个我们知道13还有15是page fault原因,我们新建一个copycow来进行解决
1 | else if (r_scause() == 15) { |
copycow,才是真实的
分配代码
- 检查pte的标识
- 接触原始映射
- 然后kalloc
- copy内容
- 之后在世新的映射,和之前原来的uvmcopy差不多
1 | // Copy cow page, |
调用了kalloc,还有kfree,会对这个页面进行初始化维1,然后减少一次,知道这个页面还有用,才不会清楚
1 | if(refcount_add((uint64)pa,-1,0)>0){ |
1 | // Allocate one 4096-byte page of physical memory. |
1 | // Free the page of physical memory pointed at by v, |
修改 copyout 函数
这点也在刚才的提示中贴心的点出来了,由于我们的 COW 页面是只读状态,那么在 kernel/vm.c 下的 copyout 函数需要进行修改。因为这个函数负责的是将一些数据从内核态复制到用户态,按照原先 xv6 的设置,copyout 是不可能预见到内存空间中的内存页只读的。
修改的办法也说不上很难,在我们通过 walk 页表取得 PTE 后先不着急转化成物理地址,而是先看一下这个 PTE 的 COW 标识位,如果有标识位那直接使用刚才的 copycow 函数,一通操作,复制到新页面修改,映射到新的物理地址映射,再继续接下来的操作:
- 首先得到pte
- 看pte有没有rsw,悠久调用cow来进行分配
1 | pte_t *pte = walk(pagetable, va0, 0); |
1 | // Copy from kernel to user. |
总结
总体来说,这一个是抄的别人写的博客。大致的原理,就是不分配内存,通过cow来分配,但是细节太麻烦了。
6.thread
用户线程切换
要求和提示
在本部分中我们将设计并实现用户级别下的线程上下文切换。开始前可以阅读 user/uthread.c 和 uthread_switch.S 下的代码,这两个文件实现了线程切换的大致框架和简单的功能测试代码,我们需要补全剩余部分。
注意到我们需要想办法创造线程并在线程切换的过程中尝试保存 / 恢复寄存器,事后如果功能实现,可以在 xv6 下运行 uthread,正确运行示例如下(三个线程的顺序可能会有出入):
1 | PLAINTEXT |
终端上的输出来自三个测试线程,每个线程都会进入一个循环,在循环中打印一行随后让出 CPU 给其他线程。但是由于现在我们还没有加入实现上下文切换的代码,我们是看不到输出的。
我们需要向 user/uthread.c 下的 thread_create() 和 thread_schedule() 中,以及 user/uthread_switch.S 下的 thread_switch 加入代码,从名字里看得出来,我们需要实现线程的创建和切换功能…
我们有两个目标需要实现,一个是我们需要确保当 thread_schedule() 第一次运行一个给定的线程时,该线程在自己的堆栈中执行 thread_create() 中给定的函数参数;另外一个是,确保 thread_switch 保存被切换走的线程寄存器,并恢复被切换到的线程寄存器,随后返回到切换过来的线程的指令中最后离开的位置。
我们需要决定在哪里存储 / 恢复寄存器,尝试修改结构体 struct thread 会是一个很好的主意。此外,我们需要在 thread_switch 中加入调用 thread_schedule(这玩意儿只有汇编代码),可以在调用时传入我们想要的任何参数,只要能从线程 t 切换到 next_thread。
相关提示:
- 在
thread_switch中我们只需要保存和恢复 callee-save 寄存器。 - 我们可以参考编译后根据
uthread.c生成的user/uthread.asm汇编代码,以方便调试。 - 为了测试代码,使用
riscv64-linux-gnu-gdb单步浏览thread_switch可能会有帮助。相关的 GDB 调试技巧,已经在 Lecture 5 介绍过了,也可以再去熟悉下。
题解
写这一个代码就是为了让我们更深入的了解,线程是如何进行切换。
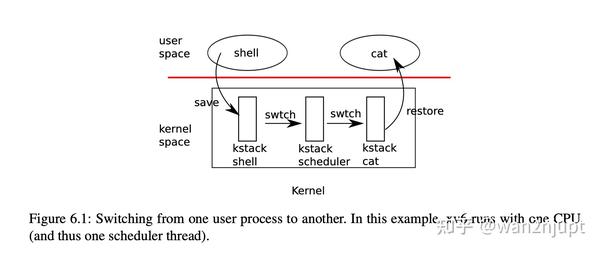
基础知识:线程切换
- shell通过中断进入内核态
- 执行yield操作,进行让位
- 使用swtch算法找到一个合适的
- 最后使用usertrapret进行返回
因为要和寄存器直接打交道,所以 xv6 选择汇编来完成,而不是 C 。相比于 C ,汇编更适合操纵寄存器,使用swtch来进行保存
1 | # Context switch |
保存当前的上下文,之后就是调度
理解了上面知识,我们知道我们这一届需要做什么了。我们就是自己模仿swtch操作,因为进程信息只有内核态可以看见,所以我们需要把这个信息传入到外面的线程数组,直接用数组来进行调用。
1 | struct thread_context { |
之后的调度程序直接抄汇编的swtch
1 | .text |
实现Switch操作
1 |
|
多线程编程
要求和提示
注意:本部分实验需要在有多核心处理器的 Linux/macOS 电脑中完成,而不是在 xv6/QEMU 下完成。
在本部分实验中,我们将使用多线程编程和锁来实现一个 HashTable 哈希表。在本次作业中我们将使用 UNIX 下的 pthread 库函数,关于 pthreads 的更多用法,可以查询 man 手册,终端上输入 man pthreads 即可,也可查询相关网页。
文件 notxv6/ph.c 中实现了一个仅在单线程下可行的哈希表,但是在多线程下运行就会产生错误。我们在主目录下运行 make ph,随后向可执行文件中传入线程数量作为参数,例如单线程执行./ph 1 即可。示例如下:
ph 程序中主要尝试运行两项测试,首先它通过 put() 尝试向哈希表中加入大量的 key,并打印出平均每秒钟执行 put 的数量,随后它尝试使用 get() 从哈希表中将 key 取出,并打印出哈希表中的 key 的数量。但是很显然目前由于没有对多线程去做额外的实现,部分的 put 操作丢失了,如下是程序未修改的情况下两个线程执行 ph 的结果,我们看到线程 put() 操作丢失了一些 key:
虽然使用两个线程使得哈希表插入的平均速度翻倍,但是带来了严重的数据丢失问题,这就是个很严重的问题需要我们解决。请仔细阅读 notxv6/ph.c,尤其是文件下的 put() 和 insert() 函数。
两个线程同时执行 put() 导致 key 丢失的原因是什么?请将作业答案保存在主目录下 answers-thread.txt 下。
为了确保相关时间的有序执行,我们需要在 put() 和 get() 中引入加锁和解锁机制。相关的 pthread 函数调用有:
1 | C |
记得不要忘记调用 pthread_mutex_init()。在这部分操作结束后,你应该可以顺利通过 ph_safe 测试,即不会有 key 丢失的状况存在。
接下来,我们尝试对哈希表的速度进行优化,在操作中有部分 put() 对内存的操作并无重叠部分,也许不需要一把很大的锁来保护哈希表(疯狂暗示减小锁的粒度),我们需要对 ph.c 做出额外的变动进而加速 put() 操作(提示:可以对每个哈希桶 bucket 各设置一把锁)。在这部分操作结束后,我们将通过 ph_fast 测试,该测试要求两个线程产生的 put() 速率是一个线程的 1.25 倍。
题解
- 优化成多线程
- 资源共享(需要加锁)
- 只有在oput的时候才需要上锁
- 注意到这里分块了bucket,所以每一个bucket都要上锁
- 每次对于一个bucket进行操作的时候,上锁put
struct entry {
int key;
int value;
struct entry *next;
};
struct entry *table[NBUCKET];
1 | struct entry { |
实现同步屏障
要求和提示
注意:本部分实验需要在有多核心处理器的 Linux/macOS 电脑中完成,而不是在 xv6/QEMU 下完成。
在这个部分中,我们需要实现一个同步屏障。也就是程序中的一个位置,所有参与的线程都需要等待直到所有其他线程都到达这个位置。我们将使用 pthread 提供的条件变量,他的机制类似于 xv6 中的 sleep 和 wakeup,我们将使用到下面这两个调用:
1 | C |
其中,pthread_cond_wait 在被调用时释放了 mutex,并在返回前重新获取了 mutex。
在 notxv6/barrier.c 下存在一个没有实现好的同步屏障,如果在没有修改的情况下运行,运行就会报错:
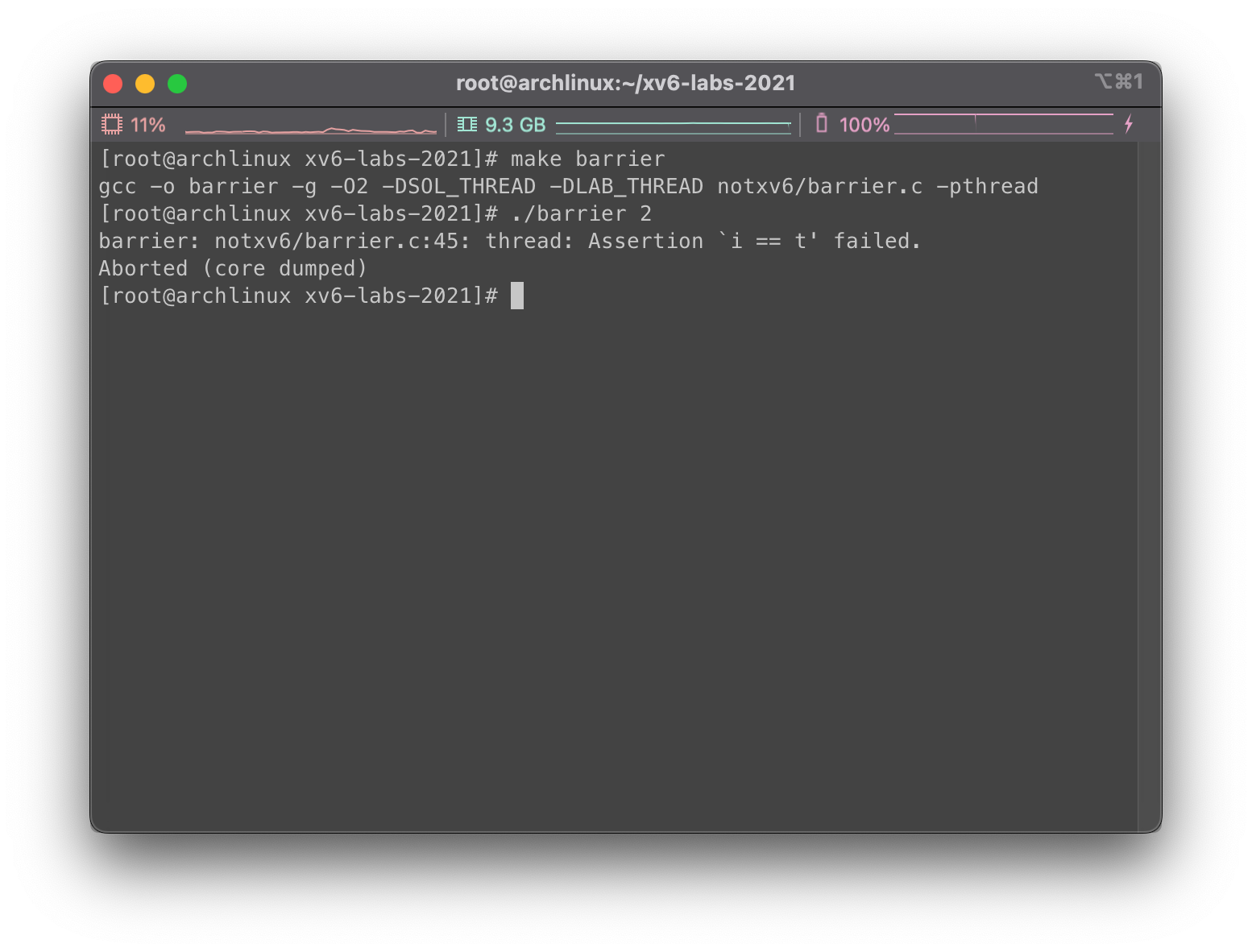
其中我们给 barrier 传入的第二个参数表示的是需要在同步屏障上进行同步的线程数量。每个线程都在执行一个循环,在每个循环中线程会调用 barrier() 然后随机睡眠若干微秒。刚才未修改的代码导致断言被触发,是因为一个线程在另一个线程到达同步屏障前就离开了。我们希望每个线程都在 barrier() 位置阻塞,直到 nthreads 个线程都调用过了 barrier()。
在 notxv6/barrier.c 中,barrier_init() 已经被给出,结构体 struct barrier 已经定义,仅供参考。我们只需要实现 barrier() 相关功能,以此来确保不会报错。
注意两个较难实现的点:
- 我们需要处理一连串的
barrier()调用,我们把这个叫做一轮。bstate.round中记录了轮数,因此每当所有线程到达内存屏障的时候我们就需要将计数加一。 - 小心处理
bstate.nthread,尤其这种情形:一个线程离开了同步屏障,其他线程还没反应过来,就进入了下一轮循环,然后又遇到了同步屏障,直接对计数加一。上一轮和下一轮的计数要分清楚。
打字已实施,只有人气了,才会对论述进行+1,不齐就是阻塞。只有齐了才全部唤醒,操作也要上锁
1 | static void |
总结
今天的实验还是比较简单,都是直接按照的讲授的内容锁撰写的。只需要明lock还有调度相关原理即可,基本可以实现。
7.lock
内存分配器加速
要求和提示
在 user/kalloctest.c 下我们实现了一个测试,在这个测试中针对 xv6 的内存分配器进行了重点测试,使用了三个进程大量的对地址空间进行增加和缩小,导致大量对 kalloc 和 kfree 的调用,其中 kalloc 和 kfree 在执行时均需要获取锁 kmem.lock。在这里我们使用 kalloctest 打印了由于另一进程已经持有了锁而在尝试自旋获取的次数,在这里使用#fetch-and-add 打印进行表示。需要指出的是,自旋的次数只能作为锁冲突的一种粗略的衡量。如果我们还没有对当前的 Lab 做出修改,我们执行 kalloctest 会得到如下类似的结果:
1 | PLAINTEXT |
可以看到 acquire 针对每一个锁,打印出了当前锁的调用次数(#acquire() 后),以及为了获取锁失败而产生的自旋次数(#fetch-and-add() 后)。kalloctest 通过调用系统调用,要求内核为 kmem 和 bcache 打印相关的计数信息,以及 5 个竞争最激烈的锁。如果发生了锁竞争,那么自旋的次数就会很大。由于在这部分实验中,我们比较关心 kmem 和 bcache 两个锁的性能,系统调用最后会返回这两个锁上发生的自旋次数的总和。
需要注意到的是,为了完成当前的 Lab,我们需要使用一台多核心独立无负载的机器。如果使用的机器上面有其他的工作负载,kalloctest 打印出的计数次数就会失去意义。
现在让我们来关注代码,在 kalloctest 中产生大量锁冲突的根本原因是 kalloc() 只有一个空闲列表。为了尽可能的规避锁冲突,我们需要重新设计内存分配器来避免一个唯一的锁和空闲列表。有一个很简单的想法,我们在每个 CPU 核心中都维护一个空闲列表,每个空闲列表有自己的锁。这样下来,在不同 CPU 下的内存分配和释放就可以并行运行,因为每个 CPU 都操作的是不同的空闲列表。这个想法实现下来最大的困难是,如何处理如下情形,一个 CPU 的空闲列表已经空了,但是另一个 CPU 仍然有空闲的内存。为了处理这样的情形,我们的 CPU 需要从别的 CPU 的空闲列表中 “偷出” 一部分空闲内存。这种 “偷窃内存” 也有可能引入锁冲突,但是希望这样会少频繁一些。
我们需要做的事情总结下来就是为每个 CPU 维护空闲列表,并当空闲列表空时从其他 CPU 处 “偷取” 空余内存。也就是说,我们需要为我们的每一个列表的锁都调用 initlock,并将名字设置为 kmem 开头。我们需要运行 kalloctest 来查看我们的实现是否减少了锁的竞争,此外为了确保实现没有问题我们还能正确分配所有的内存,我们需要运行 usertests sbrkmuch 测试。我们需要通过 test1 和 test2 测试,测试的相关输出示例如下:
1 | PLAINTEXT |
相关提示:
- 我们可以使用
kernel/param.h下的NCPU常量表示 CPU 数量。 - 使用
freerange为当前运行freerange的 CPU 提供所有空余内存。 - 函数
cpuid可以返回当前的 CPU 核心编号,但是只有在中断处于关闭状态时调用才是安全的,我们需要使用push_off()和pop_off()来控制中断的关和开。 - 可以看看在
kernel/sprintf.c下是怎么实现格式化字符串的。当然,我们将空闲列表锁的名称设置为kmem也是完全可以的
题解
1.,我们在每个 CPU 核心中都维护一个空闲列表,每个空闲列表有自己的锁。这样下来,在不同 CPU 下的内存分配和释放就可以并行运行,因为每个 CPU 都操作的是不同的空闲列表。
2.一个 CPU 的空闲列表已经空了,但是另一个 CPU 仍然有空闲的内存。为了处理这样的情形,我们的 CPU 需要从别的 CPU 的空闲列表中 “偷出” 一部分空闲内存。这种 “偷窃内存” 也有可能引入锁冲突,但是希望这样会少频繁一些。
根据题意我们锁需要做的就是
- 对每一个cpu都进行设置kmem
- 使用
freerange为当前运行freerange的 CPU 提供所有空余内存。 - 如果当前cpu不够就进行偷取其他的,同事要跳过当前cpu
1 | struct { |
首先是设置cpu个数,然后初始化锁,还有刚开始,吧所有线程分给0号,之后在进行偷取
1 | kinit() |
根据之前我们讲到的有,首先需要freerange,吧这个内存放到当前的cpu,需要重新写一个程序,因为kfree这个函数被多个其他函数调用。我们需要修改这个kfree—cpu,按照kfree的写法修改
1 | void |
最后就是kalloc的实现,主要就是实现偷取,进行遍历
1 | void * |
磁盘缓存加速
要求和提示
在本部分中实验与上半部分互相独立,如果愿意也可以先做这部分,前部分结果并不会影响当前部分的完成。
当多个进程尝试大量的使用文件系统时,锁 bcache.lock 就会产生大量的冲突,这个锁的功能就是在 kernel/bio.c 中保护磁盘块缓存。我们的测试程序 bcachetest 会创建多个进程,并不断的读取不同的文件来触发锁 bcache.lock 上的冲突,在我们还没有完成 Lab 前,bcachetest 输出类似如下:
1 | PLAINTEXT |
具体输出的数字可能有所差异,但是肯定可以看到 bcache 锁由于不断 acquire 产生的自旋尝试次数会变得很高。在 kernel/bio.c 中,我们可以看到 bcache.lock 保护了缓存块列表,包括每个块中的引用数 b->refcnt 以及缓存块的信息(b->dev 和 b->blockno):
1 | C |
我们的目标是修改缓存块使得在 bcachetest 测试中,由于对尝试锁 acquire 产生的自旋次数尽可能的少且接近零。理想状态下,块缓存中涉及所有锁的尝试自旋次数之和应该为 0,但是总和小于 500 也是可以接受的。我们需要修改 bget 和 brelse,使得 bcache 中的涉及不同缓存块的查找和释放时更不容易在锁上发生冲突(例如,不需要所有操作都等待 bcache.lock)。同时,我们需要确保每个磁盘块只会有一份缓存。
当完成时,我们的输出示例如下:
1 | PLAINTEXT |
在 initlock 中,我们需要给我们创建的每个锁一个名字,以 bcache 开头,。
相比刚才的 kalloc 内存分配,这里处理减少对于缓存块的竞争问题更加棘手,因为 bcache 缓冲区是在进程、CPU 之间共享的。对于 kalloc 来说,我们可以为每个 CPU 安排一个空闲列表来解决,在这里却是行不通的。我们需要使用一个哈希表来查询块编号,并给每一个 bucket 桶设置一把锁。
这些情况下,如果发生锁冲突我们认定是可以接受的:
- 当两个进程同时操作相同的块编号时,在
bcachetest中的test0我们不会这样测试。 - 当两个进程同时没有命中缓存,并需要寻找一块没有被使用的缓存块进行替换时。我们在
bcachetest中的test0下也不会这样测试。 - 当两个进程操作的块编号在你用来划分区块和锁的方案中发生冲突时;例如,两个进程给定的块编号映射到了同一个哈希表的 bucket 桶中。这是完全有可能的,
bcachetest中的test0有可能会这样做,这完全取决于我们的设计,但我们应该尝试调整方案的细节以避免冲突(例如,改变哈希表的大小)。
和 test0 相比之下,test1 中将测试操作更多不同的块编号,并大量使用文件系统的代码路径。
相关提示:
- 请阅读 xv6 教材 PDF 中关于块缓存的描述(见 8.1~8.3 节)
- 为哈希表设置固定数量的桶是可以的,可以不去动态调整哈希表的大小。另外可以使用质数数量的桶(例如 13)来减少散列冲突。
- 在哈希表中搜索块编号,如果没有命中我们再重新分配条目,这两个操作需要是原子的。
- 我们需要删除所有缓存块列表(
bcache.head等),改为使用缓冲区的最后时间(即使用kernel/trap.c下的ticks来记录时间戳)。这样修改后,brelse就不需要获取bcache锁,bget也可以根据时间戳选择最久没有使用的块。 - 在
bget中序列化地进行驱逐是可行的(即bget中选择缓存块的部分,当查找缓存未命中时可以选择一个缓存块重新使用)。 - 我们的答案在一些情形下需要使用两把锁;例如,在驱逐缓存块期间,我们可能需要持有
bcache和哈希表 bucket 下的锁。请确保不会发生死锁。 - 当我们尝试替换一个缓存块,我们可能需要将一个缓冲块从一个桶 bucket 转移到另一个桶 bucket。我们可能会遇到棘手的问题,也就是新的块可能哈希到与旧的块相同的桶,务必注意不要发生死锁。
- 一些调试小技巧:实现 bucket 锁的时候,可以先在
bget的开始和结束位置留下全局的bcache.lock的加锁解锁。当我们尝试解决了竞争问题,尝试运行测试的时候再去掉全局锁,处理并发问题。我们也可以使用make CPUS=1 qemu来使用单独一个核心来进行测试。
题解
- 哈希表设置固定数量的桶是可以的,可以不去动态调整哈希表的大小。另外可以使用质数数量的桶(例如 13)来减少散列冲突。
- 希表中搜索块编号,如果没有命中我们再重新分配条目,这两个操作需要是原子的
这一节需要我们对磁盘有一定的了解

文件的基本构造,首先最下面进行操作 的是disk,之后我们通过对bcache进行操作,然后写入disk,logging是负责记录操作的日子,为了房子电脑停电crash,inode则是每一个虚拟dev对应的数据结构,通过对pathname我们来得到文件夹dinode
现在我们来看buf cache的数据结构
1 | struct { |
可以看出则是一个双向链表,则是实现lru来进行构造的,buf数组是所有的缓存区文件,head是为了好进行lru才构造的。我们现在的目的是制作多个head,发散到不同的头上面,然后来进行删除
根据上面的提示,我们把这一整个链表分成多个段,使用13座为三列值,三列函数,使用dev+blockno,来得到
1 | struct |
真正的底层操作还是在hashtable,每一个hashtable都是单独的一个双向链表,我们还是在单独的双向链表进行操作,但是初始化,吧所有的节点还是挂到0号,之后和上面一样进行偷取
首先还是进行lock初始化
1 | void binit(void) |
接下来就是什么时候更新会见戳,当我们这个这个数据结构引用次数是0的时候,就需要进行更新了,之前是直接自己进行lru算法实现,现在我们只需要吧这个变成当前时间就可以
1 | void brelse(struct buf *b) |
1 | void |
最后就是如何进行偷取,bget的任务就是根据给定dev还有blockno来进行得到所需要的buf。下面是2中解决
我们是首先根据他的id,来算出他是哪一个bucket里面的,之后对这个bucket来进行遍历,看这个buf存不存在。不存在,就是用lru策略,使用时间戳来进行换出。如果是没有空闲节点,那就需要进行偷取,遍历其他bucket,然后找到空闲的,之后修改这个空闲的dev还有no来进行偷取
- 获取当前的bucket
- 查看有没有他
- 没有就查看有没有空闲节点,使用lru换出
- 也没有,就使用lru偷取别人的
1.查找bucket,看有没有缓存可以使用的
1 | truct buf *b; |
2.没有,就从自己的空闲使用lru
1 | // Not cached. |
还是没找到,就偷取别人,找到就break’
1 | if (!victm) |
最后就是如果找到了,就进行初始化,更换dev,还有block,还有ref,同事还有进行打开和释放链表,双向链表得到操作
1 | if (victm) |
下面是全部操作的代码
1 | static struct buf * |
总结
第一个内存分配的题目是送分题目,基本上只要看懂题目就知道如何理解。第二个这个也是参考别人的实现,有的是没使用单链表,这个博主的思路和之前代码基本一样比较好理解,就对这个博主的代码进行了参考。
8.fs
大文件实现
要求和提示
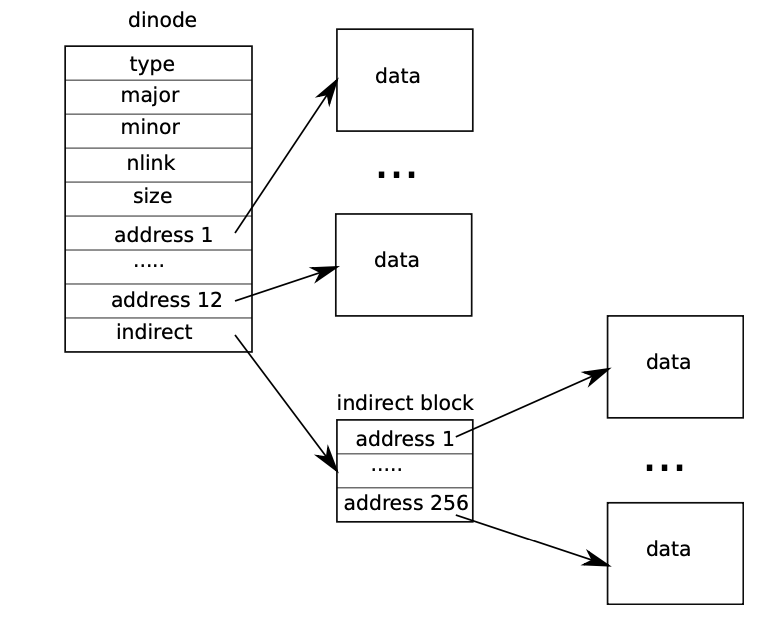
在这个部分中,我们将为 xv6 提高其文件系统所能支持的最大文件大小。当前 xv6 所支持的最大文件大小被限制在 268 个块,也就是 268*BSIZE 个字节(在 xv6 中 BSIZE 块内存大小为 1024)。这个限制的原因来自在 xv6 的 inode 中,存储有 12 个 “直接” 块编号和一个 “间接” 块编号,在 “间接” 块编号指向的块中又可以存储 256 个块编号。因此,一个文件最多可以对应 12+256=26812+256=26812+256=268 个块。
这是在 PDF 中图 8.3,很好的表示了这一结构:
在这部分作业中,我们将使用 bigfile 进行测试能创建的最大文件,如果我们暂时还没有对当前 xv6 修改,我们会获得这样的结果:
1 | plaintext |
题解
这一个题目是408考了很多次的题目,直接看提示就可以写的。首先设置最大的文件块长度,是直接+一级+二级,二级索引是一级*一级。之后把地址进行变成addr+2,0 -addr-1是直接,addr是一级,addr+1下标代表的是二级。同事inode还有dinode也要更新,之后就是进行分配。
1 |
|
分配,是在一级之后来进行二级
1 | // Inode content |
删除也是一样的操作,首先获取地址,然后对这个网页在进行遍历,之后再次进行删除,直接抄袭一级索引就行
1 | // Truncate inode (discard contents). |
符号链接实现
要求和提示
在这一部分中,我们将为 xv6 添加符号链接(软链接)功能。符号链接通过路径名指向一个被链接的文件;当一个符号链接被打开时,内核会跟踪符号链接访问对应的文件。符号链接类似于硬链接,但是硬链接只仅限于指向同一磁盘的文件,而符号链接可以跨越磁盘。虽然 xv6 不支持多设备,但是实现这个系统调用是一个很好的练习,可以帮助我们了解路径名查询的工作原理。
我们的目标是实现系统调用 symlink(char *target, char *path),他将在指定路径上创建一个新的符号链接,指向由目标命名的文件。想了解更多用法,我们可以查看 symlink 的 man 页面。为了测试 symlink 系统调用,我们需要向主目录下 Makefile 文件中加入 symlinktest(添加系统调用的基操,忘记了的话去重温下 Lab Syscall)。成功的 symlinktest 运行结果示例如下:
1 | C |
相关提示:
- 首先,为
symlink创建一个新的系统调用编号,在user/usys.pl和user/user.h中添加条目,并在kernel/sysfile.c中实现sys_symlink。(不记得的强烈建议重新去看一下 Lab Syscall) - 向
kernel/stat.h中添加一个新的文件类型T_SYMLINK,以表示符号链接。 - 我们需要在
kernel/fcntl.h中添加一个新的标志O_NOFOLLOW,我们可以与open系统调用一起使用。请注意,传递给open的标志是按照位检测的,所以新标志不应当与现有的标志位重叠。在添加标志位之后,只要我们将symlinktest加入到 Makefile 中,user/symlinktest.c就可以顺利通过编译。 - 我们将实现
symlink(target, path)系统调用,在指定目录下创建一个指向目标的新符号链接。需要注意的是,系统调用的成功并不需要目标的存在。因此,我们需要选择一个地方来存储符号链接的目标路径(例如,在 inode 下的数据块中)。最后symlink应当返回一个整数,代表成功(0)或者失败(-1),类似于link和unlink。 - 我们需要修改
open系统调用,以处理路径指向符号链接的情况。如果该文件不存在,open系统调用需要返回失败。当一个进程在打开标志中指定O_NOFOLLOW标志位时,open应当打开链接(但不跟踪符号链接)。 - 如果被链接的文件也是一个符号链接,我们必须递归地跟踪他,直到到达一个非链接文件。如果链接形成了一个循环,我们需要返回一个错误代码。我们也可以提前设定一个阈值(例如 10),当链接的深度到达阈值就返回错误代码来近似地处理这个问题。
- 其他系统调用(例如
link和unlink)则不能跟踪符号链接,这些系统调用只能操作符号链接本身。 - 在这个 Lab 中,我们不需要处理指向文件夹的符号链接。
题解
- 首先是设置symlin,这个之前就讲了很多就不在讲了
- 之后添加文件类型
- 然后对symlink进行实现,得到两个str
- 通过create来进行穿件文件类型,之后就是写入targetpath到这个inode里面
- 之后对open操作,进行修改,加入判断是不是软连接,然后次数要不要进行递归
1 | uint64 sys_symlink(void){ |
1 | if(ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)){ |
总结
终于写完大部分的6.s081,从4月份开始写,一直拖到现在,才填完坑。羞愧。中间一个月去复习软考了。
本身自己是非科班跨考408的,对于操作系统还有计算机组成都只停留在背诵还有做题阶段。对原理却是什么都不知道。
当第一次写第一个作业的时候,我连如何使用ide来辅助编写代码都不会。文件是make文件,我之前之后使用集成IDE来进行一键编译调试,但是第一次我都不知道如何进行调试代码,看着视频里的教授使用gdb调试代码。我都不知道这到底是怎么实现的。
我只好从网上搜索vscode调试6.s081.但是大多数人都知识给了一个一个task还有一个launch.json没有解释是为什么可以调试成功。然后直接复制粘贴进行运行,按住f5来进行调试,再加上前面的题目我几乎都没有自己思考的过程,于是5月份我就准备软考,没有接着写了。
6月份,考完之后,我有重新开始把这之前了题目在做一遍。同时,我具体进行了研究一下,vscode的两个json文件到底是干什么。首先第一个task,顾名思义就是你自己想要进行的任务操作,例如编译就可以是gcc a.c -o a.out直接进行简化,相当于配置好了手动输入的麻烦。接下来的launch.json才是重点
,我们可以设置gdb来进行调试,调试的文件是kernel(因为操作系统最开始初始化的文件就是kernel,首先进行内存加载
,之后设置远程调用gdb,这个是作业里面教授设置的,然后就可以按住f5来进行调试。相当于真正的启动程序。注意还需要我们手动输入make qemu-gdb在命令行。这个任务正好可以被我之前讲解的task来解决,我们只要在task新加一个任务输入 make就行。到这里才真正明白是如何进行调试gdb的。
之后差不多到了那种全忘了的境界,然后去上考场,重新写入题目,可能也是因为软考也复习了一下操作系统吧,做起题目来,比之前好多了,之前没有理解的视频也逐渐就豁然开朗的感觉,重新做会题目前4个,就感觉很快。后面的文件部分,就做的比较慢一点,可能是当初也没复习好文件。
总的来说xv6这个操作系统还是让我对内,存加载,页表操作,陷入内核态,进程切换,这些概念有实打实的认识。不想之前学408只知道什么调度算法,什么直接相连,全相连这种概念性的东西对整个操作系统如何启动,如何使用系统调用,程序如何中断,为什么要换页,出现page falut,还有如何进行线程切换都有了一个打字的了解,可能果断时间就会网络吧。所以记录一下。
最后感谢,网络上这些大佬的题解,不然,我几乎就就有可能放弃了,有些 题目都是参考大佬的题解才实现的。

