

语雀同步到hexo
语雀同步到hexo简介你是否有过这样的烦恼,数据存到云上会有不安全,数据丢失的风险,或者是你有不同的数据需要存放到不同的地方,例如飞书作为读书笔记,语雀作为内容输出(因为语雀可以有免费的会员,飞书储存有限)。这些都导致数据在不同的地方,不是一个的输出。因此需要把数据进行备份到hexo。
这里使用的是elog软件进行同步,你需要进行配置好语雀的token还有github图床的token。具体教程如下
部署教程参考官网的快速开始
https://elog.1874.cool/yuque/start
1npm install @elog/cli -g
之后进行初始化
1elog init
官网的示例
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990module.exports = { ...
Hello World
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
Quick StartCreate a new post1$ hexo new "My New Post"
More info: Writing
Run server1$ hexo server
More info: Server
Generate static files1$ hexo generate
More info: Generating
Deploy to remote sites1$ hexo deploy
More info: Deployment

第二周,GIN入门
1.入门首先最简单的直接抄袭官网的快速开始,常见的三步。1.定义server的断开。2.设置路由对应handle函数。3.设置handle函数
设置server
设置对应的处理函数,匿名函数,传入的是ctx是关键
开始run
路由匹配参照spring的request param和正则匹配
通过param来获取参数,这个与java@request param取值差不多的思路
还有一种是在?这种参数,查询参数,使用query进行获取
设置register函数
当需要注册的路由太多,我们需要进行调用的server.get次数就会很多次。可以进行抽象出来一个方法,放到专属的类,每一个路由都在类里面就有处理方法。
下面就是优雅之后的代码。
分组路由相当于spring的requestmapping放入到类最前面的路径
通过ug来接着子路径
数据接受vo传输与java类似,传输数据前后端,使用的需要vo,pojo来进行json传输数据。不同的是java可以自动封装传输的数据位class对象,这边需要把前后端的进行映射才能组装位vo,使用的是反引号·
这个也与email小写就是私有 ...
第一周,go语言拾遗
本节主要讲解的是go语言的基础语法,主要参照的是自己的遗留问题。
文件路径package和java里面的包一样,也是需要先定义好文件夹路径
package的名字可以与文件夹的名字不一样,同一个文件夹下面的包名药一直,test文件除外
基础数据和java差不多也是int,uint,float这些
数字的极限,只能通过使用math包来进行获取
string与python类似,使用反引号这是个特点`进行作为字符串
常量与变量使用var来进行定义,这个与js差不多,自动类型推断,先写变量名称在写类型,与rust差不多。
。通过使用大小写来作为pubilc与private的进行区别。
使用:=来进行类型推断。只有局部变量才可以
常量,使用const来进行修饰。这个字不可以进行修改的
iota进行自增加,主要是自我增加。
方法声明常见的代码,首先 定义是函数,然后设置名称和类型。
可以返回多个类型与python类似
返回值的接受与变量差不多,直接使用:=来进行接受返回值。
函数式编程
主要思想就是把函数作为参数,然后如果要使用函数,直接加上()进行调 ...
场景优化
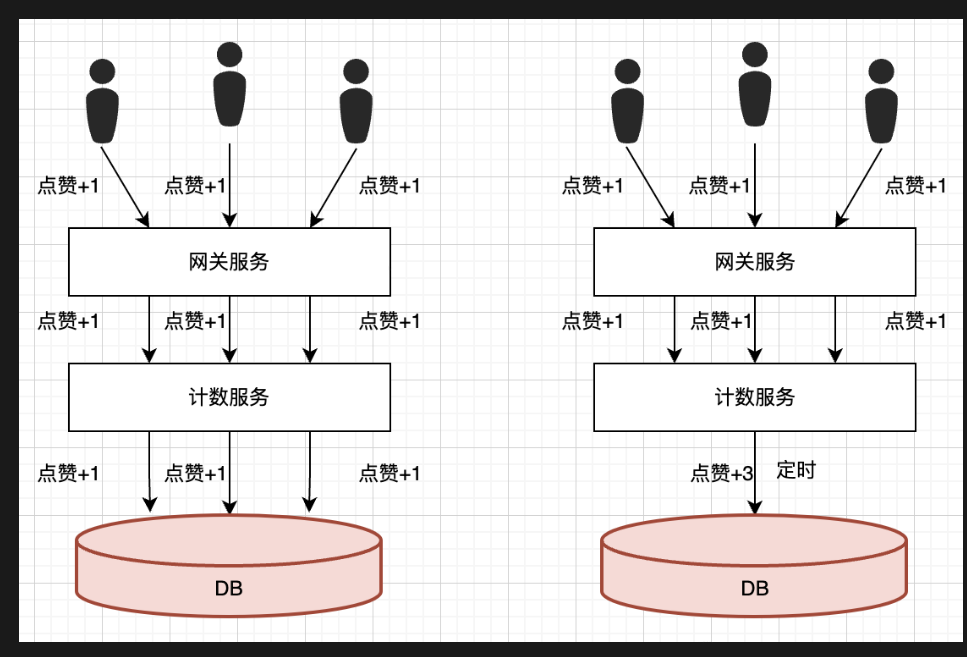
聚合写上一章节场景题目,介绍的点赞系统,就是使用的聚合写操作,之前点赞都是每次一次,可以在内存里面聚合之后,然后再进行100个合在一起的,进行一次加100,减少数据库的压力
或者数据库进行批量插入,
普通的接口,没有聚合,使用压测 wrk,900qps
@schedule 是进行定时逻辑,调用次数300来使用
场景题目
两种思路,一个是4个d
询问场景,询问qps,主要业务,业务流程
询问服务,主要是暴露什么接口
接下来就是storage,使用什么数据库还有schma,为什么不用其他
接下来就是看还有没有优化的,进行防止盗刷,限流什么的
还有caps
沟通c,进行交流,业务逻辑,qps,精准度要求(能不能多卖,还是少买),难点分析
a架构,服务,存储,流程
p观点展开,难点1,难点2
s总结,开场出结论,然后索引要点
秒杀专题c对话主要询问qps,业务流程,难点
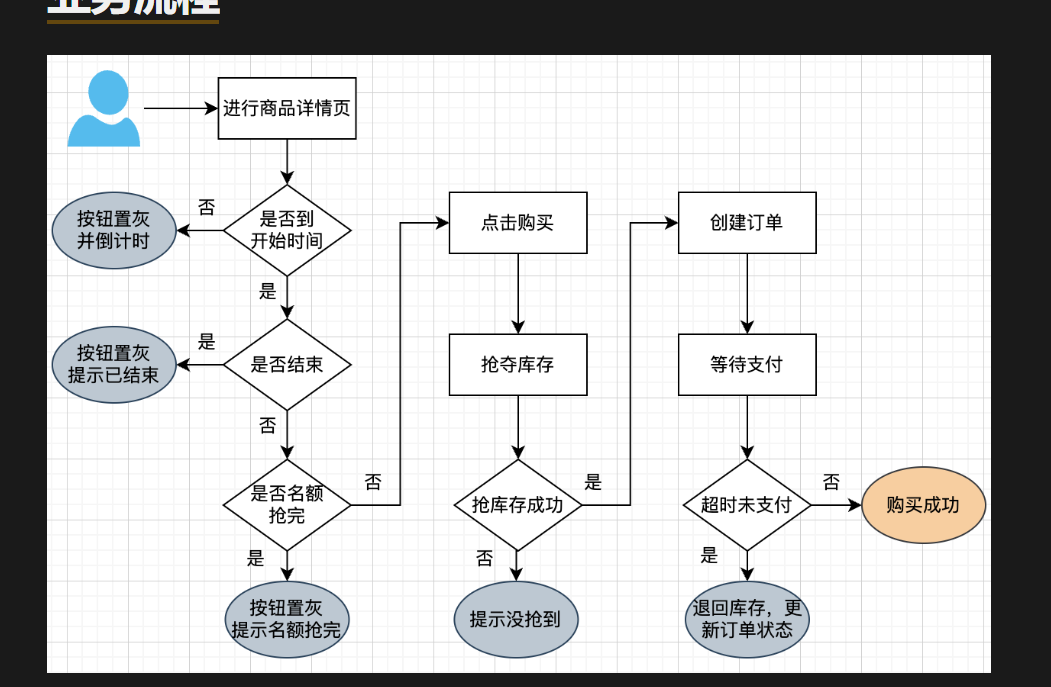
主要的业务流程:首先是查询时间是否到了秒杀时间,之后开始秒杀,是否还有名额,然后进行购买,秒杀库存,之后生辰订单,付款
请求量估计,如果是一般的5k,单个mysql就行,1w两个mysql,超过直接上redis,10w之后就是集群,每一个redis配置下平均的秒杀数量
超卖与少买的问题,使用redis、
redis寄了,丢掉命令
主从切换,丢了
查询不是原子的
少买
库存减少,但是订单失败
用户不付款,回滚失败
难点分析
高并发,人流量大-风控,限流,验证码,薛峰
高精准
大吉黄牛,进行限额
架构设计主要是进行服务,存 ...

海量数据题目
所谓海量数据处理就是在大数据情况下来处理具体情况就是内存有限,数据太大无法处理完成所有,因此需要使用特殊处理。
常见的方案就是
时间换空间,使用bitmap,哈希,trie树灯解决
空间换时间,进行hash到小文件,然后统计小文之后归并统计
常见的方案
分治
外排序
划分
bitmap
trie树
倒排序
分治方案顾名思义:就是数据量太多,无法一次性装入到内存,就会hash小文件,统计小文件的
统计访问最多的ip地址
题解:
使用hash取模1000,分到1000小文件
之后维护一个hashmap来计算频率,可以得到前1000个最大的ip
然后使用快排或者使用堆排序
统计300w里面的热门10个查询
大约只有300w个有效,然后就是计算长度300*1k/4=0.75G,可以直接丢到内存进行处理结果
使用hash进行计算ip对应的值
然后直接堆排序,是Nlogk
有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词2^30/2^4 = 2^26
2^20/2^4 ...

智力题
智力题一半都是都是在面试腾讯时候才会进行面试的问题,常见的问题就是包括烧绳子
烧绳子问题
题意:使用两个如何得到15分钟。
题解:可以进行对着烧,就是两边一起烧绳子,结果就是加速得到绳子,就是半小时了稍晚第一根绳子,然后第二根绳子还有半小时,接下来对第二根绳子接着对半烧,那就是只有15分钟了
最少试剂问题
这个是常见的的二进制编码问题,直接进行分组二进制按第一位是1的,第二位是1的
题意:使用最少的来进行检测那些人有病
题解:直接二进制检测,第一根试剂看有没有毒,第二根试剂看又没有毒,第三根有没有毒然后01二进制编码
或者直接使用二分法则,看那一边有问题,50,25,13,7,4,2,1
过桥问题
过桥问题
在漆黑的夜里,甲乙丙丁共四位旅行者来到了一座狭窄而且没有
护栏的桥边。如果不借助手电筒的话,大家是无论如何也不敢过
桥的。不幸的是,四个人一共只带了一只手电筒,而桥窄得只够
让两个人同时过。如果各自单独过桥的话,四人所需要的时间分
别是T1、T2、T3、T4分钟(假设T1<T2<T3<T4);而如
果两人同时过桥,所需要的时间就是走得比较慢的那个人单独行
动时所 ...